
$800K Lost Because a Model Thought the City Was Empty
See how moving to atomic hashes slashed P99 latency by 170ms and why Spark Streaming is costing you an extra $30,000 monthly.


Zenith Mobility is a late-stage Series D mobility startup that recently hit 100 million completed rides globally. They have expanded into 15 new international markets in the last eighteen months, scaling their fleet to nearly 2 million active drivers.
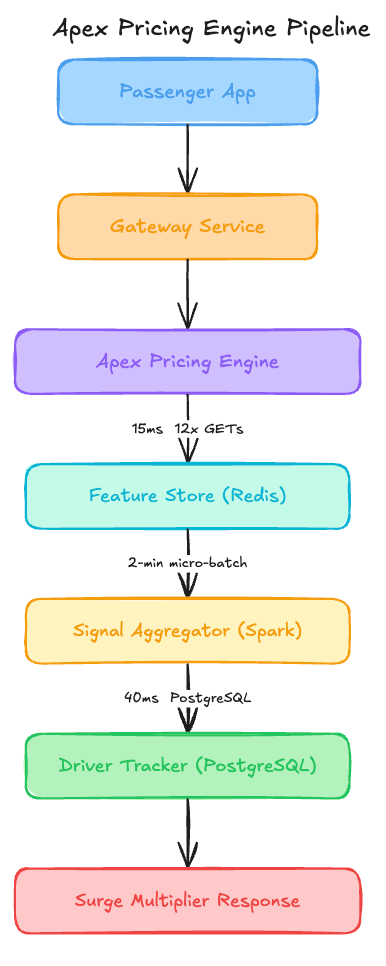
Their engineering team built a dynamic pricing engine called Apex that powers the surge multiplier for every ride request in real-time. Here is their setup.
Architecture Overview
When a passenger opens the app, the request triggers a price estimation flow to determine the surge multiplier.
Traffic patterns
Average rides per day: 1.2 million
Peak rides per hour: 280,000
Average: 4,000 req/sec
Peak: 15,000 req/sec
The ML Pipeline:
The model is a Gradient Boosted Decision Tree (XGBoost) trained on 180 days of historical ride data, including demand density, driver proximity, and external factors like weather. It outputs a multiplier between 1.0x and 4.0x. The feature vector consists of 12 real-time signals fetched from the Redis feature store.
Current performance:
P99 Latency: 280ms
Reliability: 99.92%
Business impact metric: $4.20 average surge revenue per peak-hour ride
Costs:
Cloud Infrastructure: $140,000 / month
Redis Managed Instance: $22,000 / month
Total: $162,000 / month
Recent incidents:
New Years Eve Peak: Systemic revenue miss of $800,000. Under-priced rides by 30% during a 4-hour window.
Recovery: Manual override of surge multipliers to a flat 2.5x across major metros once the discrepancy was caught by Finance.
The Analysis
Now let me show you what’s actually happening here.
Critical Issue 1: Stale Feature Confidence
I write about ML systems in production — the tradeoffs, the architecture decisions, the stuff that doesn’t make it into papers. If you want to go deeper, the paid tier covers the technical details I can’t fit in free posts.
