
67. Improving RAG components.

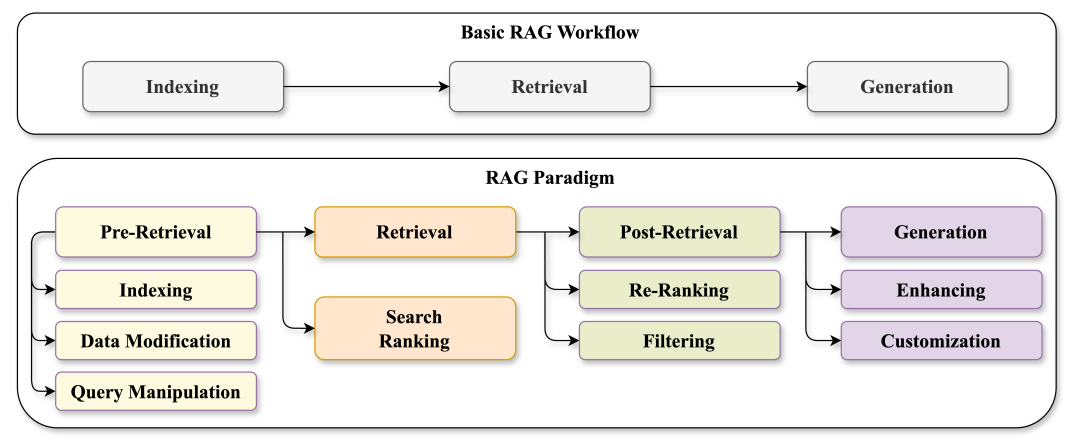
Introduction
At this point, if you are reading this newsletter you have somewhat of a grasp of what RAG is: “Use the query to retrieve documents from a DB, put the documents as context for the LLM, use LLM to asnwer the query".
Easy right?!
While developing something like the above will make you feel like you are the x10 machine learning engineer, it’s actually quite naive. It will probably work 80% of the times. For a toy project, that’s good.
But for a system that should scale to millions of requests, it’s not enough!
Let’s see how you can improve upon it.
1. Improving Ingestion
In the context of enhancing the ingestion process for the RAG components, adopting advanced chunking strategies is necessary for efficient handling of textual data.
Better chunking strategies
The following strategies are being used recently:
Content-Based Chunking: Breaks down text based on meaning and sentence structure using techniques like part-of-speech tagging or syntactic parsing. This preserves the sense and coherence of the text. However, one consideration of this chunking is it requires additional computational resources and algorithmic complexity.
Sentence Chunking: Involves breaking text into complete and grammatically correct sentences using sentence boundary recognition or speech segment. Maintains the unity and completeness of the text but can generate chunks of varying sizes, lacking homogeneity.
Recursive Chunking: Splits text into chunks of different levels, creating a hierarchical and flexible structure. Offers greater granularity and variety in text, but managing and indexing these chunks involves increased complexity.
Better indexing strategies
Improved indexing allows for more efficient search and retrieval of information. When chunks of data are properly indexed, it becomes easier to locate and retrieve specific pieces of information quickly. Some improved strategies include:
Detailed Indexing: Chunks through sub-parts (e.g., sentences) and assigns each chunk an identifier based on its position and a feature vector based on content. Provides specific context and accuracy but requires more memory and processing time.
Question-Based Indexing: Chunks through knowledge domains (e.g., topics) and assigns each chunk an identifier based on its category and a vector of characteristics based on relevance. Aligns directly with user requests, enhancing efficiency, but may result in information loss and lower accuracy.
Optimized Indexing with Chunk Summaries: Generates a summary for each chunk using extraction or compression techniques. Assigns an identifier based on the summary and a feature vector based on similarity. Provides greater synthesis and variety but demands complexity in generating and comparing summaries.
2. Improving Retrieval
The introduction of hypothetical questions involves generating a question for each chunk, embedding these questions in vectors, and performing a query search against this index of question vectors. This improves search quality due to higher semantic similarity between queries and hypothetical questions compared to actual chunks.
HyDE
Instead, HyDE (Hypothetical Response Extraction) involves generating a hypothetical response given the query, enhancing search quality by leveraging the vector representation of the query and its hypothetical response.
Context enrichment
Sentence Window Retrieval: Embedding each sentence in a document separately to achieve high accuracy in the cosine distance search between the query and the context. After retrieving the most relevant single sentence, a context window is extended by including a specified number of sentences before and after the retrieved sentence. This extended context is then sent to the LLM for reasoning upon the provided query. The goal is to enhance the LLM's understanding of the context surrounding the retrieved sentence, enabling more informed responses.
Auto-Merging Retriever: In this approach, documents are initially split into smaller child chunks, each referring to a larger parent chunk. During retrieval, smaller chunks are fetched first. If, among the top retrieved chunks, more than a specified number are linked to the same parent node (larger chunk), the context fed to the LLM is replaced by this parent node. This process can be likened to automatically merging several retrieved chunks into a larger parent chunk, hence the name "auto-merging retriever." The method aims to capture both granularity and context, contributing to more comprehensive and coherent responses from the LLM.
Fusion retrieval or hybrid search
This strategy integrates conventional keyword-based search approaches with contemporary semantic search techniques. By incorporating diverse algorithms like tf-idf (term frequency–inverse document frequency) or BM25 alongside vector-based search, your system can harness the benefits of both semantic relevance and keyword matching, resulting in more thorough and inclusive search outcomes.
Reranking and filtering
Post-retrieval refinement is performed through filtering, reranking, or transformations. LlamaIndex provides various Postprocessors, allowing the filtering of results based on similarity score, keywords, metadata, or reranking with models like LLMs or sentence-transformer cross-encoders. This step precedes the final presentation of retrieved context to the LLM for answer generation.
Query transformation
Query Expansion: Query expansion decomposes the input into sub-questions, each of which is a more narrow retrieval challenge. For example, a question about physics can be stepped-back into a question (and LLM-generated answer) about the physical principles behind the user query.
Query Re-writing: Addressing poorly framed or worded user queries, the Rewrite-Retrieve-Read approach involves rephrasing questions to enhance retrieval effectiveness. The method is explained in detail in the paper.
Query Compression: In scenarios where a user question follows a broader chat conversation, the full conversational context may be necessary to answer the question. Query compression is utilized to condense chat history into a final question for retrieval.
Query routing
The question of where the data resides is crucial in RAG, especially in production settings with diverse data-stores. Dynamic query routing, supported by LLMs, efficiently directs incoming queries to the appropriate datastores. This dynamic routing adapts to different sources and optimizes the retrieval process.
3. Improve Generation
The last step is generally the least significant as it’s heavily dependent on the quality of your LLM. Aside from better prompting, you can try:
Iterative Refinement: Refine the answer by sending retrieved context to the Language Model chunk by chunk.
Summarization: Summarize the retrieved context to fit into the prompt and generate a concise answer.
Multiple Answers and Concatenation: Generate multiple answers based on different context chunks and then concatenate or summarize them.
Conclusion
With the additional toolset, you can now pinpoint the quality bottleneck of your RAG application and go and fix it!
Let me know if you are using one of these techniques in your day job! :)
Ludo