
Alibaba’s EST: Decoupling Compute from Sequence Length in CTR Scaling

TL;DR
Scaling CTR models usually hits a wall between model size and inference latency. Alibaba’s new architecture, EST (Efficiently Scalable Transformer), bypasses this by avoiding early aggregation of user behavior sequences.
Instead of standard self-attention, they introduce Lightweight Cross-Attention (LCA) to exploit information density asymmetry and Content Sparse Attention (CSA) to handle multimodal signals with linear complexity.
Introduction
The industry is currently obsessed with applying LLM-style scaling laws to Recommendation Systems. The theory is sound: larger models and more data should equal better predictions, however the engineering reality is brutal.
In CTR prediction, increasing sequence length (user history) or model width typically results in a latency penalty that production environments cannot tolerate.
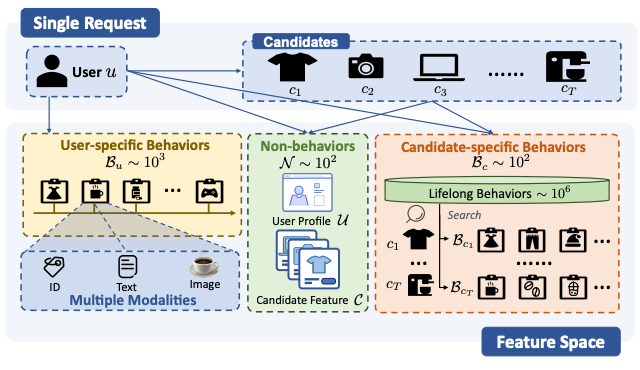
To mitigate this, most standard architectures (like DIN or standard Transformers) rely on hierarchical modeling. They compress the user behavior sequence into a fixed-length representation early in the pipeline before mixing it with target item features. The authors of this paper argue that this early aggregation is a lossy compression bottleneck that prevents true scaling.
However, “Unified Modeling” where you concatenate user behaviors, candidate items, and context into one massive sequence for full self-attention is computationally prohibitive because of the quadratic complexity relative to sequence length. The authors address this trade-off by analyzing the specific information density of CTR inputs.
The Architecture of EST
The core thesis of the Efficiently Scalable Transformer (EST) is that not all token interactions matter. In LLMs, tokens are relatively homogeneous. In CTR, there is a massive asymmetry between “Non-behavioral” features (user profile, context) and “Behavioral” sequences (history).
The authors utilize this asymmetry via two main mechanisms:
Lightweight Cross-Attention (LCA)
Standard self-attention computes an all-to-all interaction matrix.
The authors found that interactions *between* behavior tokens (e.g., a user clicked a shoe yesterday vs. a hat today) provide diminishing returns. The high-signal interactions happen between the Non-behavioral features (the “Query”) and the Behavioral sequence (the “Key/Value”).
LCA hard-codes this prior. It forces the Non-behavioral tokens to attend to the Behavioral tokens, but prevents the Behavioral tokens from attending to themselves or each other within this module.
This effectively decouples the computational cost from the sequence length in terms of interaction complexity. Crucially, because the user behavior sequence processing is agnostic to the specific candidate item in this stage, the keys and values for the behavior sequence can be computed once and cached across all candidates in a single request.
Content Sparse Attention (CSA)
Handling multimodal features (images, text descriptions) in CTR usually involves massive embedding tables or heavy encoders. The authors observe that content signals work best as “relational priors” rather than raw tokens.
CSA uses pre-trained, frozen content representations to compute a similarity matrix between items in the sequence. Instead of learning attention weights from scratch, they use this fixed similarity map to guide attention.
They apply a Top-K sparsification (only keeping the K most similar items), which reduces the complexity of this module to linear time.
This allows the model to capture semantic relationships (e.g., visual similarity between clicked items) without the overhead of training distinct attention heads for content.
Final takes on what matters most
The most significant takeaway here is the successful decoupling of user-side computation from candidate-side computation within a Transformer backbone.
In a typical high-throughput serving setup (scoring thousands of candidates per user request), full attention requires re-computing the entire sequence interaction for every candidate. By restricting the architecture so that user behavior processing doesn’t depend on the specific candidate ID until the final interaction layers, EST allows for significant computation reuse.
From a scaling perspective, the authors demonstrate that EST adheres to power-law scaling curves. As they increased model depth and width, performance improved monotonically. This is not always a given in RecSys, where adding parameters often leads to overfitting or diminishing returns faster than in NLP.
By maintaining the token-level granularity of the behavior sequence deeper into the network—without paying the quadratic cost—they capture fine-grained signals that pooling layers like Sum-Pooling or Attention-Pooling often wash out.
For engineers working on systems where the user history length is the primary bottleneck, EST offers a blueprint for processing 1,000+ length sequences within millisecond-level latency budgets.