
Beyond Immediate Click: Engagement-Aware and MoE-Enhanced Transformers for Sequential Movie Recommendation

TLDR:
This paper from Amazon Prime Video presents a sophisticated, multi-component ML system for sequential movie recommendation that moves beyond predicting simple clicks. The key innovations are:
Personalized Hard Negative Sampling (PHNS): Uses user-specific movie completion rates to create more challenging and informative training examples.
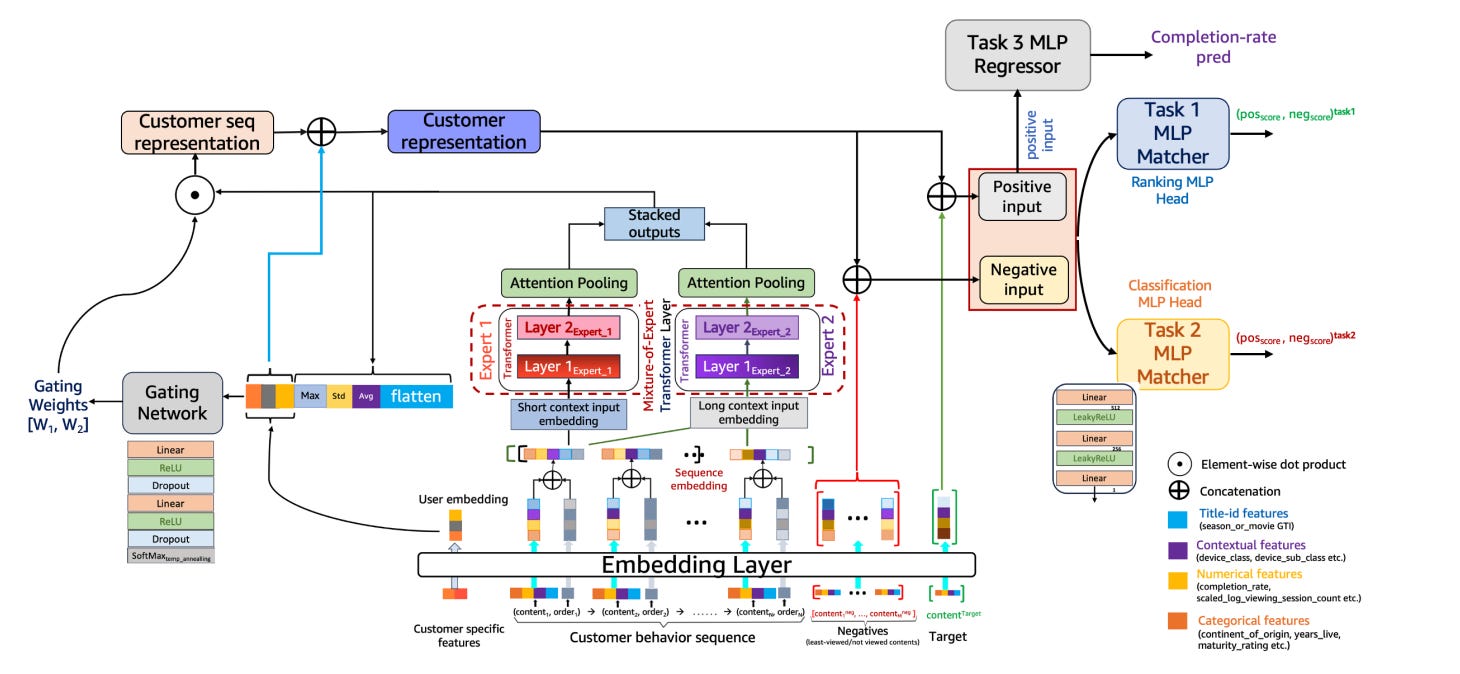
Specialized Mixture-of-Experts (S-MoE): Employs different Transformer “experts” that specialize in short-term vs. mid-term user behavior, with an adaptive gate to route users to the appropriate expert.
Engagement-Aware Personalized Loss: A multi-task learning framework that jointly optimizes for CTR and ranking, but weights the loss function based on how much of a title a user actually watched. This directly aligns the model’s objective with user satisfaction.
Next-K Prediction: Extends the model to forecast the next several titles a user might watch, not just the immediate next one, using a “soft-label” training strategy.
The result is a system that outperforms a strong baseline by up to 3.52% on NDCG@1, demonstrating a more robust and engagement-focused approach to recommendation.
Introduction: Moving from Click Prediction to Engagement Optimization
In large-scale recommender systems, optimizing for Click-Through Rate (CTR) is standard practice. However, a high CTR doesn’t always translate to user satisfaction—a phenomenon often called “clickbait bias.” A user might click on a title but abandon it after a few minutes, signaling a poor recommendation.
The engineering team at Amazon Prime Video addresses this gap with a unified framework built on a Behavioral Sequential Transformer (BST).
Their work details a full-system approach that tackles deficiencies at every stage of the modeling process: from data sampling and model architecture to the loss function itself. This design is a blueprint for building recommenders that learn what users will not only click on, but what they will genuinely engage with.
System Architecture: Adaptive Experts and Smarter Data Curation
The core of the proposed system is an enhancement of the standard BST model, focusing on two key architectural and data-level improvements.
First is the Adaptive Context-Aware Mixture-of-Experts (MoE) architecture.
Instead of a single monolithic Transformer, the system uses multiple “expert” networks. Critically, these are not generic experts; they are specialized. One expert is trained on short sequences of user interactions (e.g., the last 7 items) to capture immediate intent, while another expert handles longer, mid-term sequences (e.g., the last 20 items) to model more stable preferences. An adaptive gating network learns to route user representations to the most relevant expert(s) based on their interaction history, allowing the model to dynamically adjust to different user contexts.
Second is a more intelligent data sampling strategy called Personalized Hard Negative-aware Sampling (PHNS).
Typical negative sampling is random or based on global popularity. This paper proposes using user-specific completion rates to mine for “hard negatives”: titles the user started watching but abandoned.
These examples are powerful because they are semantically close to the user’s interests but were ultimately not satisfying. Training on these forces the model to learn the nuanced boundary between a good and a bad recommendation for a specific user, far better than training on obviously irrelevant random negatives.
Training Objective: Beyond CTR with Engagement-Aware Multi-Task Learning
Perhaps the most impactful component is the re-framing of the optimization objective. The system uses a multi-task learning (MTL) framework to jointly optimize three distinct but related tasks:
CTR Prediction: A binary classification task.
Ranking Optimization: A contrastive loss-based task to ensure relevant items are scored higher than irrelevant ones.
Completion Rate Prediction: A regression task to estimate how much of a title a user will watch.
The key innovation here is the Engagement-Aware Personalized Loss.
The standard binary cross-entropy (for CTR) and contrastive (for ranking) losses are dynamically weighted by a user-specific scaling factor derived from the completion rate. For example, a positive interaction where a user watched 95% of a movie will contribute more significantly to the loss calculation than an interaction where they only watched 15%. This aligns the model’s gradient updates with a direct proxy for user satisfaction.
Furthermore, the system extends its prediction horizon to a Next-K forecasting task. To train this, they use a soft-labeling approach where the immediate next title gets a positive label of 1.0, the second-next gets 0.6, and the third gets 0.3. This teaches the model to consider the user’s longer-term journey while still prioritizing the accuracy of the most immediate recommendation.
Main Takeaways for MLEs
Your Negative Samples Define Your Model’s Capability: The success of PHNS is a strong reminder that thoughtful data curation is as important as model architecture. Instead of random sampling, leverage user-specific engagement signals (e.g., completion rate, dwell time, bounce rate) to find challenging negative examples that will teach your model fine-grained user preferences.
Align Loss Functions Directly with Business Value: Moving beyond generic loss functions like BCE is crucial. The paper’s personalized loss, which incorporates completion rate, is a prime example of how to encode a key business metric (user satisfaction) directly into the training objective.
Use MoE for Specialization, Not Just Scale: The MoE architecture here isn’t just about increasing parameter count efficiently. It’s a deliberate design choice to have different parts of the model specialize in different contexts (short-term vs. mid-term behavior). Consider if your users exhibit distinct modes of interaction that could be handled by specialized experts.
Architect for the Entire User Journey: The shift from next-item to Next-K prediction reflects a more realistic view of user behavior. The soft-labeling technique is a practical engineering solution to balance immediate accuracy with long-term foresight, preventing the model from being diluted by noisy future signals.
Synergy Matters: The strength of this work lies not in a single component, but in how PHNS, S-MoE, and the personalized MTL objective work together. Real-world performance gains often come from designing a cohesive system where each component addresses a specific weakness in the overall modeling pipeline.
The personalized hard negative sampling approach is clever. Using completion rates to idnetify titles users abandoned is way more informative than random negatives. I'd be curious how they handle edge cases where users drop off for non content reasons like interuptions. The MoE architecture makng sense here too, especialy with the adaptive gating between short term and mid term experts.
Thanks for writing this it clarifies a lot. What if S-MoE's adaptive gate misroutes user behavior?