


Beyond RAG: Search-R1 Teaches LLMs to Learn How to Search

Introduction
We all know Large Language Models (LLMs) are incredibly powerful, but they often hit a wall when it comes to complex reasoning or needing truly up-to-the-minute information.
They might rely on outdated internal knowledge or struggle to effectively use external tools like search engines.
Current solutions like Retrieval-Augmented Generation (RAG) help by injecting search results into the prompt, but it's often a one-shot deal, limited by the initial query, and the LLM doesn't learn a better search strategy.
Prompting LLMs to use search engines as "tools" (like in ReAct or IRCoT) is another approach, but the LLM isn't fundamentally trained to optimize its interaction with the search tool – it's just following instructions. Training models via supervised fine-tuning requires massive datasets of ideal search interactions, which are hard to create and scale.
Search-R1: Learning to reason and search via RL
Instead of just giving the LLM search results or telling it when to search, Search-R1 lets the LLM figure it out through trial and error, rewarding it when it finds the correct answer.
How Search-R1 Works:
Interleaved Reasoning and Search: The LLM (an extension of DeepSeek-R1) learns to generate text step-by-step. When it realizes it needs external information, it autonomously generates a search query within special tokens (<search>query</search>).
Real-Time Retrieval: The system catches this, executes the search, and feeds the results back to the LLM wrapped in <information>...</information> tokens.
Multi-Turn Interaction: The LLM can then reason further (<think>...</think>) based on this new information and decide if it needs to search again, potentially multiple times for complex questions.
Learning via Simple Rewards: Crucially, the training doesn't rely on complex, hand-crafted rewards for how it searched. It primarily uses a simple outcome-based reward: did the final answer (<answer>...</answer>) match the ground truth?
Stable RL Training: They introduced a clever technique called "retrieved token masking" to ensure the RL process focuses on learning reasoning and query generation, not on trying to optimize the already retrieved text, leading to more stable training.
Results:
Search-R1 was tested on seven question-answering datasets, including tricky multi-hop ones. The results are significant:
Outperformed Strong Baselines: Search-R1 showed average improvements of 26% (Qwen2.5-7B), 21% (Qwen2.5-3B), and 10% (LLaMA3.2-3B) compared to methods like RAG, IRCoT, and even standard RL-tuned reasoning models (R1) without search capabilities.
Works Across Models: The technique proved effective for both base LLMs and instruction-tuned variants, and across different model families (Qwen, Llama).
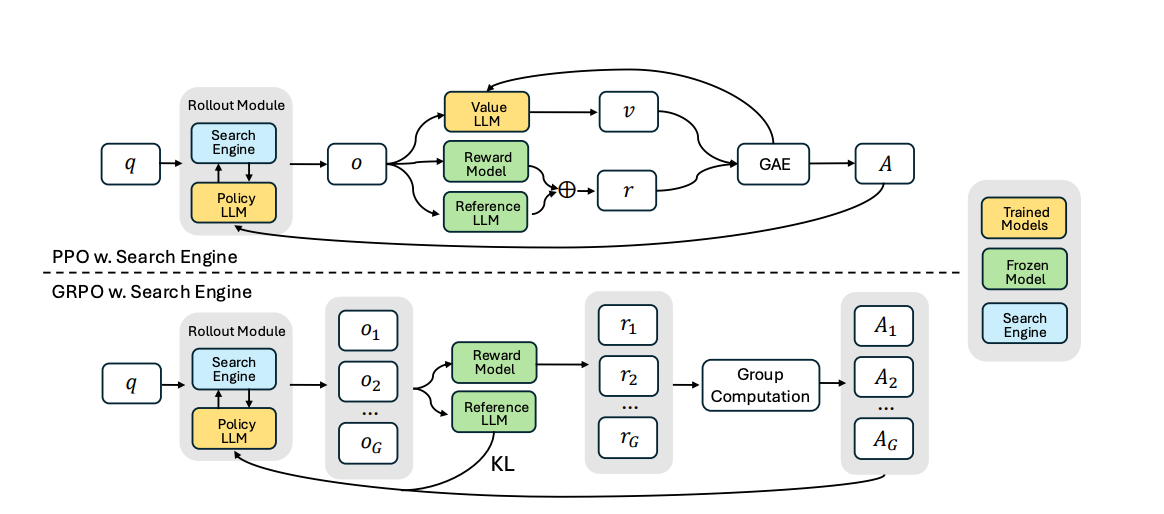
Learns Efficiently: Even starting from base models, RL helped them catch up to instruction-tuned models in performance, demonstrating the power of learning through feedback. The researchers also shared insights into using different RL algorithms (PPO vs. GRPO) and observed how the model's response length changed dynamically as it learned to search effectively.
Why I think it’s important
Search-R1 represents a significant step towards building LLMs that can more autonomously and effectively interact with the dynamic world of external information. By learning how and when to search as part of their reasoning process, these models can become:
More accurate and less prone to hallucination.
Capable of tackling more complex, knowledge-intensive tasks.
More adaptable, as they learn interaction strategies rather than just following pre-programmed steps or relying on static retrieved context.
This RL-based approach avoids the need for massive, labelled interaction datasets required by supervised methods, making it potentially more scalable.