
ByteDance’s TokenMixer-Large: Scaling Ranking Models
Mixing and Reverting

TL;DR
ByteDance has released a successor to RankMixer that solves the gradient vanishing issues found in deep ranking models.
The core innovation is a “Mixing & Reverting” block structure that aligns token dimensions to allow proper residual connections in deep networks.
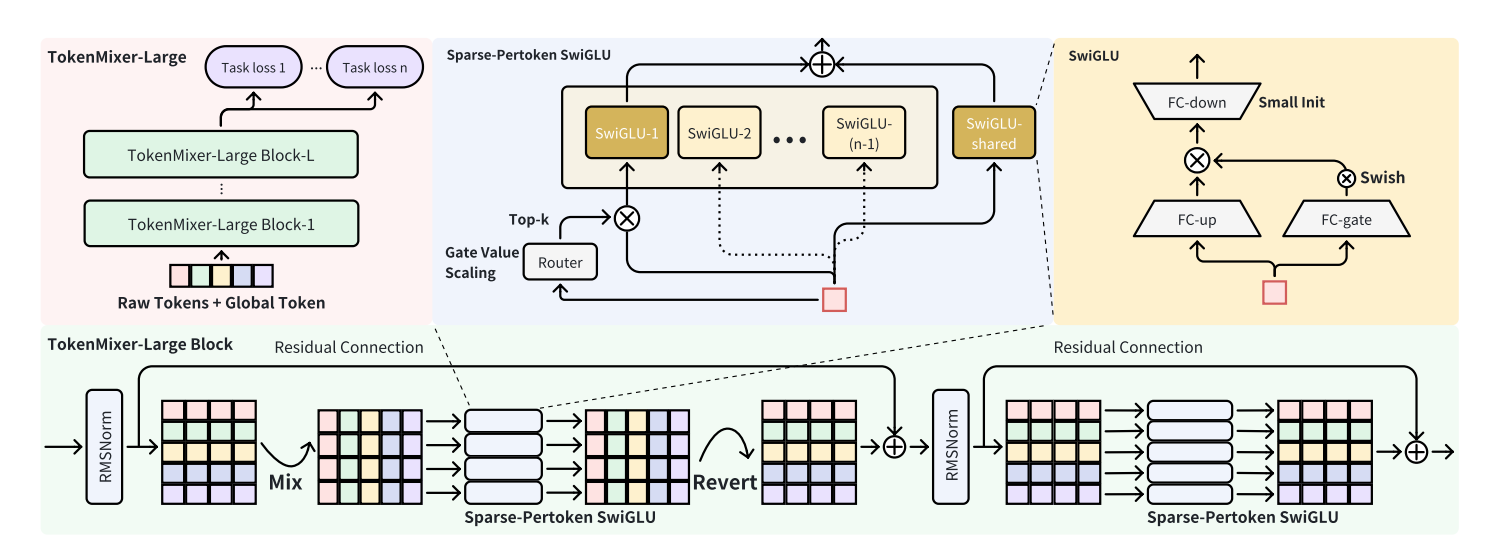
They aggressively removed memory-bound operators in favor of a “pure” architecture dominated by matrix multiplications, achieving 60% Model FLOPs Utilization (MFU). The model uses a Sparse-Pertoken MoE with a “first enlarge, then sparse” strategy and scales to 7B parameters in production.
Introduction
In the recommendation systems world, the industry is chasing the same scaling laws that power LLMs. However, scaling Deep Learning Recommendation Models (DLRMs) is notoriously difficult. Unlike dense language models, DLRMs rely on massive embedding tables and sparse features, making them memory-bandwidth bound rather than compute bound.
RankMixer successfully replaced expensive self-attention with lightweight token mixing (similar to MLP-Mixer). But it hit a wall: when they tried to make it deep, performance plateaued or degraded. The mixing operations changed token dimensions, breaking the semantic alignment needed for effective residual connections.
TokenMixer-Large is the engineering response to that bottleneck.
It is a system designed specifically to enable extreme depth in ranking models without losing gradient signal, validated on traffic serving hundreds of millions of users.
Mixing, Reverting, and Pruning
The architecture relies on three distinct technical shifts: a symmetric block design, a “pure” model philosophy, and a specific flavor of MoE.
1. The Mixing and Reverting Paradigm
The primary failure mode of the original RankMixer was its residual design. Standard ResNets require the input x to be added to the output F(x). In RankMixer, the mixing layer compressed tokens (e.g., mixing N tokens into M), altering the semantic meaning and dimension. Adding the original tokens back to this mixed representation created a semantic mismatch.
TokenMixer-Large solves this with a symmetric two-step process within each block:
- Step 1 (Mixing): Information is mixed among original tokens, changing the dimension.
- Step 2 (Reverting): A second layer restores the dimension of the mixed tokens to match the input.
This “Mixing-Reverting” symmetry ensures the input and output of the block are semantically and dimensionally aligned.
This allows for a clean “identity mapping” initialization, meaning gradients can propagate through very deep networks without vanishing.
2. The “Pure” Model Architecture
Historically, ranking models are Frankenstein monsters of various operators, bagging together DeepFM, DCN, LHUC and others.
These legacy operators are often memory-bound (low compute intensity, high memory access).
The authors found that at scale, a stack of generic TokenMixer blocks captures the same benefits as these specialized operators. They removed the fragmented operators entirely. The resulting model is almost exclusively composed of Grouped GEMMs (General Matrix Multiplications).
This shift transforms the workload from memory-bound to compute-bound, which is exactly what GPUs are designed for.
3. Sparse-Pertoken MoE
To scale parameters without blowing up inference latency, they use a Mixture of Experts (MoE). However, they adopt a specific strategy: “First Enlarge, Then Sparse.”
- They first train a dense model to maximum capacity.
- They then split the feed-forward network (FFN) weights into experts.
- They employ a “Gate Value Scaling” trick: multiplying router logits by a constant factor (reciprocal of sparsity) to ensure gradients are large enough to update the selected experts, solving the convergence issues often seen in sparse training.
Production engineering take aways
This paper is significant because it provides a blueprint for moving RecSys infrastructure closer to LLM infrastructure.
High Hardware Utilization (MFU)
Optimization engineers often struggle to get DLRMs above 10-20% GPU utilization because the kernels are too small and scattered. By stripping out the fragmented operators and focusing on a “pure” structure, TokenMixer-Large achieves 60% MFU. This is an incredibly high number for a ranking model. It means you are getting maximum value out of your H100s or A100s, rather than letting them idle while fetching memory.
Token Parallelism for Inference
Serving a 7B parameter ranking model is non-trivial due to strict latency SLAs (usually <50ms). The authors introduce “Token Parallelism” to handle this. Standard tensor parallelism requires All-to-All communication which is slow.
- In Token Parallelism, the model shards the data along the token dimension.
- The “Mixing” step splits tokens across devices.
- Because the block structure ends with “Reverting,” the data stays sharded until the very end of the block.
This reduces the communication overhead from 4 steps per layer to just 2 steps plus one final sync, resulting in a 29% throughput gain in serving.
Quantization and Convergence
The paper confirms that FP8 serving (using E4M3) works for large ranking models, providing a 1.7x speedup with negligible AUC loss. They also note that larger ranking models require significantly more data to converge. Scaling from 500M to 2B parameters required 4x the training data duration (60 days vs 14 days of logs) to fully saturate the model’s capacity.
This work suggests that the era of complex, hand-crafted feature interaction layers (like xDeepFM) is ending.
The future of industrial ranking is stacked, uniform blocks that leverage scale and hardware-friendly matrix operations.
The biggest takeaway for me is that scaling only works when the architecture stays efficient enough to handle real production workloads