
Can Vision-Language Models complete popular video games?
and a cool swiss startup that is making a business out of it!

Introduction
In today’s article, I will talk about Vision-Language Models (VLMs) and their application to video games.
In the end, I will also share a cool AI startup that is using them to automate QA for gaming companies.
The question is:
“Can VLMs handle task like intuitive perception, spatial reasoning and adaptive memory management that humans naturally possess? “
Just took a look at a paper [1] that introduces a new benchmark: “VideoGameBench," which pits frontier models against classic video games.
These games serve as an ideal testbed for evaluating whether AI systems are developing similar inductive biases.
VideoGameBench distinguishes itself through its setup:
Task: Models must attempt to complete a suite of 10 diverse video games (seven public, three kept secret to test generalization) from the Game Boy, Game Boy Color, and MS-DOS eras.
Input Modality: Agents receive only raw visual game frames. This is paired with initial textual instructions detailing high-level objectives (e.g., "defeat the final boss") and game controls (e.g., "press 'A' to jump").
Strictly Unassisted Play: The benchmark explicitly prohibits game-specific hints, visual overlays, direct access to internal game states (like emulator RAM), or any human-assisted intervention during gameplay. This forces a direct evaluation of the VLM's intrinsic ability to perceive, reason, and act based purely on multimodal input.
Benchmark Construction & Key Features:
Diverse Environments & Mechanics: The game selection (including titles like Doom II, Kirby’s Dream Land, Zelda: Link’s Awakening, Sid Meier’s Civilization I, The Incredible Machine) spans a wide array of genres (FPS, platformer, action-adventure/RPG, strategy, puzzle). This exposes VLMs to varied challenges: 2D and 3D navigation, real-time reaction, physics-based puzzles, strategic planning, and interactions requiring both controller-style button presses and mouse/keyboard inputs.
Standardized Emulation: A framework abstracts underlying emulators (PyBoy for Game Boy, DOSBox/JS-DOS via Playwright for MS-DOS) to provide a consistent, reproducible interface for agent communication.
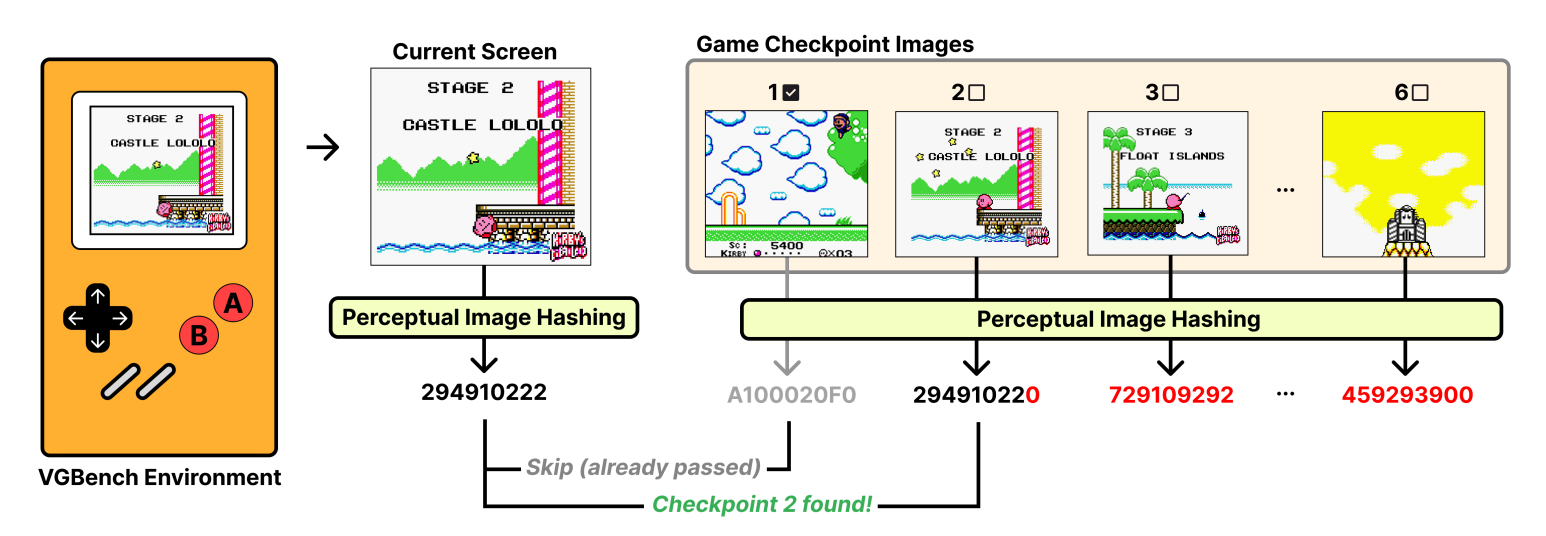
Novel Automated Progress Tracking: Moving beyond binary pass/fail, VideoGameBench introduces an innovative method for fine-grained scoring. YouTube walkthroughs with timestamped milestones are scraped. During an agent's playthrough, perceptual hashing (e.g., pHash) is applied to the game frames. The Hamming distance between these hashes and pre-scraped checkpoint frame hashes quantifies game progress.
Testing Generalization with Secret Games: The inclusion of three secret games directly addresses the challenge of overfitting, pushing for agent designs that can adapt to genuinely unseen environments.
Deep Dive: The Experimental Setup
The methodology employed to evaluate these powerful models is key to understanding the results:
The VG-Agent: Researchers implemented a "VG-Agent" leveraging the ReAct (Reason+Act) framework. This enables the VLM to generate an internal "thought" or reasoning trace before committing to an action, a crucial step for tackling complex, multi-step problems.
Inputs to VG-Agent:
An initial prompt providing high-level game objectives and explicit control instructions.
Visual Input: For standard VideoGameBench, a single frame is provided 0.5 seconds after an action is taken (actions themselves are brief, e.g., 0.1 seconds).
Contextual History: The last few frames and the agent's own previous observations/actions are fed back into the model.
Memory Mechanism: A basic form of short-term memory was implemented. After each step, the VLM was prompted to articulate information it deemed important to store in a textual scratchpad. This allows the agent to attempt to track game state, objectives, or learned strategies.
Action Output: VLMs generated actions in natural language (e.g., "press_key space", "hold 'Up' for 2 seconds"), which were then parsed and executed by the emulator.
Models Under Test: The evaluation encompassed several leading VLMs, providing a snapshot of current SOTA capabilities:
GPT-4o (gpt-4o-2024-08-06)
Claude Sonnet 3.7 (claude-3-7-sonnet-20250219)
Gemini 2.5 Pro (gemini-2.5-pro-preview-03-25)
Gemini 2.0 Flash (gemini-2.0-flash) (selected for its potential for faster inference)
Llama 4 Maverick (Llama-4-Maverick-17B-128E-Instruct-FP8) (representing open-source models)
Evaluation Constraints & Integrity:
To manage resources and prevent unproductive infinite loops, runs were terminated if insufficient progress towards the next checkpoint was detected.
A crucial validation step involved a human player attempting games using the exact same restricted interface as the VLMs. The human's ability to progress confirmed the interface's viability, suggesting the limitations observed were primarily attributable to the VLMs themselves.
Budget constraints limited runs to one per model per game. However, a small variance study with Gemini 2.5 Pro indicated low run-to-run variability.
VideoGameBench Lite: Decoupling Reasoning from Reaction Speed
Recognizing that VLM inference latency could be a significant confounder in real-time games, the researchers introduced VideoGameBench Lite:
In this mode, the game emulator pauses while the VLM processes visual input and formulates its next action. The game only resumes momentarily to execute the chosen action.
For DOS games in Lite mode, the agent received five past frames (spaced 0.1s apart), offering a richer immediate visual history. For Game Boy games, the most recent frame was provided.
This modification effectively transforms real-time games into turn-based interactions, allowing for a clearer assessment of the agent's planning and decision-making capabilities, isolated from the pressures of rapid response.
Performance of Frontier VLMs
The results paint a picture of significant challenges for current VLMs:
VideoGameBench (Real-time): Performance was extremely limited. The top-scoring model, Gemini 2.5 Pro, achieved an overall score of only 0.48% (average completion across all 10 games). It managed to reach the first checkpoint in just one game (Kirby’s Dream Land DX, with 4.8% completion). Other leading models like GPT-4o (0.09%) and Claude Sonnet 3.7 (0%) fared no better.
VideoGameBench Lite (Paused): While performance improved, it remained modest. Gemini 2.5 Pro, GPT-4o, and Claude Sonnet 3.7 all achieved an overall score of 1.6%, again largely driven by reaching the first checkpoint (4.8% completion) in Kirby's Dream Land. Even without latency pressure, games like Doom II and Link's Awakening saw 0% progress.
Practice Games: To further dissect capabilities, three simple custom PC games were devised (Location Clicking, Mouse Dragging, 2D Navigation). While models like Claude Sonnet 3.7 and Gemini 2.5 Pro mastered the clicking game, they struggled significantly with mouse dragging (requiring precise continuous control) and 2D maze navigation.
Key Multimodal and AI Challenges
These results go beyond just game-playing and touch upon fundamental challenges in AI and multimodality:
Robust Multimodal Grounding: The core task requires VLMs to deeply ground linguistic concepts (objectives, controls) in rapidly changing visual scenes. The low scores suggest that current models struggle to consistently and accurately map visual percepts to semantic understanding and then to appropriate actions, especially when the visual input is raw and noisy.
The "Knowing-Doing Gap": A recurring failure mode observed was the "knowing-doing gap." Models would sometimes articulate a correct understanding of the immediate goal (e.g., "the door is at the bottom of the screen") but then fail to execute the correct sequence of actions to achieve it (e.g., repeatedly pressing "down" regardless of the character's current position). This points to a disconnect between high-level reasoning and low-level motor control generation.
Visual Processing Limitations: Agents frequently misinterpreted visual information. Examples include wasting ammunition on already defeated enemies (misperceiving them as alive) or incorrectly inferring an interaction with an NPC had occurred simply by being visually proximal in a previous frame. This indicates that VLM visual systems may lack the robustness for fine-grained, stateful interpretation in dynamic contexts.
Long-Horizon Planning and Memory in Open Worlds: Games like Zelda or Doom II require remembering explored areas, tracking quests, managing resources, and forming multi-step plans. The ReAct agent with its textual scratchpad proved insufficient. Models often got stuck in loops, overwrote crucial memory, or failed to retain salient information over extended periods, highlighting a critical weakness in current architectures for tasks requiring persistent, structured memory and foresight.
Inference Latency vs. Real-Time Interaction: The significant performance delta between VideoGameBench and VideoGameBench Lite starkly illustrates that the computational cost and latency of large VLMs are major bottlenecks for any application requiring real-time responsiveness.
Generalization to Novelty: The poor performance across a diverse set of games, including the secret ones, underscores the difficulty VLMs face in generalizing learned skills or common-sense reasoning to new, unseen environments, even if those environments share mechanics with games they might have encountered in their pre-training data. True zero-shot generalization in complex interactive domains remains elusive.
Credit Assignment in Sequential Decision Making: In games, the reward for an action might be significantly delayed. It's challenging for models, especially without explicit reward signals (as in this benchmark), to learn which actions in a long sequence contributed to success or failure.
A cool 🇨🇭 Swiss 🇨🇭 AI startup working on this
A really cool AI startup that is doing a lot of (hard, as we have just seen) work in the space is nunu.ai.
They essentially plan on using agents to automate QA testing for gaming companies.
They have made a lot of cool progress there and already have some partnerships.
Take a look at one of their alpha test run:
Go check them out, they are hiring! :)
This is crazy! Major use case for game/level testing, although I think it could stretch far beyond that.
P.S I'd pay for an Agent that could beat Dark Souls ' bosses in one go, haha