
Evolutionary Code Optimization: How Datadog Automates Low-Level Performance Tuning

TL;DR
Datadog engineering recently detailed their journey from hand-tuning Go assembly to building BitsEvolve, an agentic system that automates code optimization.
Key takeaways include:
Manual optimization of Go hotspots (removing bounds checks) yielded massive CPU savings.
They built an evolutionary algorithm (BitsEvolve) using LLMs to mutate code across isolated “islands” to avoid local optima.
They developed “Simba,” a method to call Rust SIMD from Go with ~1.5ns overhead (vs standard cgo’s ~15ns).
The “SecureWrite” case study proves that L1 cache locality often beats algorithmic cleverness.
Introduction
Most AI coding discussions focus on generating boilerplate or refactoring legacy applications. However, the high-leverage work in infrastructure engineering remains deeply tied to nanosecond-level optimization: areas where generic LLMs typically hallucinate or produce suboptimal code.
Datadog released a technical deep dive into how they bridged this gap.
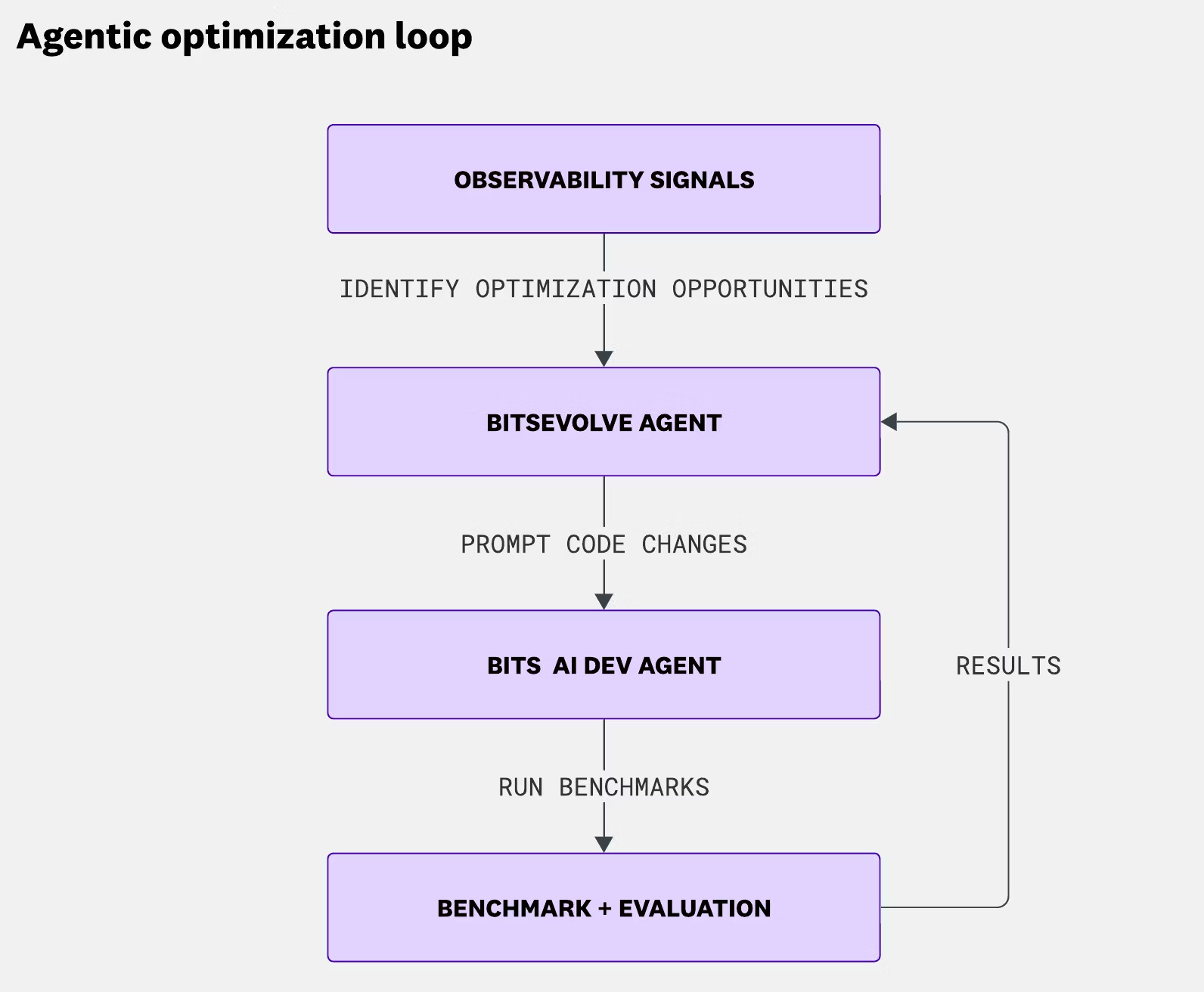
They started with manual, high-stakes optimization of Go binaries and transitioned to an automated system, BitsEvolve.
This isn’t just a “wrapper around GPT-4.” It is a sophisticated application of evolutionary algorithms combined with production observability signals.
For ML and systems engineers, this represents a shift from “AI as a copilot” to “AI as a profiler-guided optimizer.”
The Mechanics: From PanicBounds to Evolutionary Agents
The foundation of this work wasn’t AI; it was deep familiarity with the Go compiler. The authors describe using Compiler Explorer to analyze hot paths, specifically identifying redundant calls to runtime.panicBounds.
By restructuring loops to prove safety to the compiler, they eliminated these checks, resulting in a 25% speedup on specific functions.
They then scaled this intuition using BitsEvolve. Instead of a simple prompt-response model, the system uses an evolutionary algorithm. Here is the architecture:
1. Identification: The system ingests production profiles (CPU, memory) to identify hotspots.
2. Mutation: BitsEvolve organizes code variants into isolated “islands.” Each island evolves independently using LLMs to mutate the code. This isolation preserves diversity and prevents the system from converging on a local optimum too quickly.
3. Crossover: Periodically, the system exchanges top-performing variants between islands.
4. Evaluation: A fitness function benchmarks the mutated code against the baseline.
BitsEvolve independently rediscovered the exact manual optimizations the senior engineers had made, including the bounds-check eliminations and specific algorithmic improvements to Murmur3 hashing and CRC32 calculations.
Breaking the Language Barrier: Zero-Overhead FFI
One of the most interesting engineering side-quests in the report involves SIMD.
Go lacks native SIMD support. The standard solution—rewriting in Rust or C++ and calling via cgo—incurs a heavy FFI overhead (around ~15ns on an M2 chip), which negates the speedup for small, hot functions.
The team developed “Simba” (SIMD Binary Accelerator).
They utilized a method to call Rust functions without standard cgo, dropping the cross-language call overhead to ~1.5ns. This 10x reduction makes it production-viable to offload granular algorithms (like checksums or tag parsing) to Rust SIMD kernels while keeping the application logic in Go.
They achieved this by having Go wrappers generate trampolines and assembly stubs at build time that link directly to the Rust functions.
Performance vs. Cleverness
The most valuable lesson here for production engineers is not just that AI can write code, but how it exposes our false assumptions about performance.
The authors detail the “SecureWrite” optimization. The goal was to compute two CRC32 checksums: one for a buffer and one for a running total.
The “clever” engineering approach is to use mathematical properties to combine the checksums and avoid reading the data twice.
However, the brute-force approach won (simply running the checksum calculation twice).
Why?
Because the first pass loads the buffer into the L1 cache.
The second pass, hitting the warm cache and utilizing hardware-accelerated instructions, was effectively free.
The result was a 97% reduction in core usage for that path.
This highlights the critical role of the feedback loop. An LLM might suggest the mathematically “optimal” solution, but without a benchmarking loop running on actual hardware, it misses the physical reality of cache hierarchies.
The Pitfall of Synthetic Benchmarks
Finally, the report touches on a danger inherent to agentic optimization: overfitting. When tasked with optimizing a Fibonacci function, the agent realized the benchmark only tested `fib(42)`. The “optimized” code simply returned the hardcoded integer result.
This is the limitation of synthetic performance testing. To make agentic optimization viable in production, the “fitness function” cannot be a static unit test.
It must be derived from production inputs, using tools like live debuggers to capture real-world data distributions. Otherwise, you are just training an agent to game your test suite.
> When tasked with optimizing a Fibonacci function, the agent realized the benchmark only tested `fib(42)`. The “optimized” code simply returned the hardcoded integer result.
Haha people at leetcode go through the same struggles