


46. Federated learning
Multiple entities collaboratively train a model while ensuring that their data remains decentralized. How?

Introduction
I really like reading about federated learning systems deployed in practical environments as they are a very interesting mix of machine learning distributed systems and basic machine learning ideas applied with a good intuition.
In federated learning (FL), only the locally trained models or computed gradients are exchanged, without exposing any data information. As a result, it is able to protect privacy to some extent.
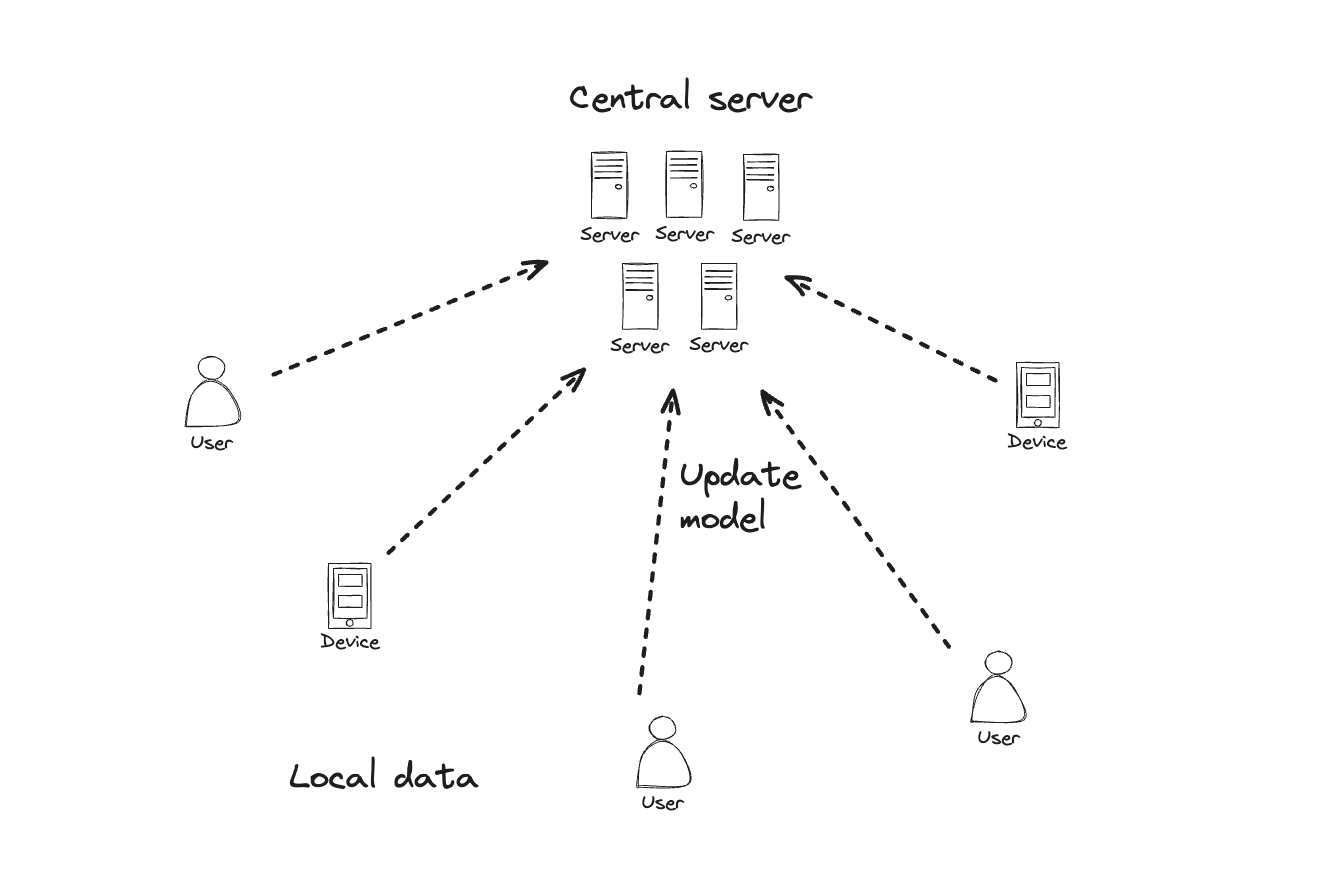
The general flow is the following:
Each party trains the local model distributed from a central cloud.
The training process is usually implemented based on SGD with local data and then generates corresponding local updates.
Second, the local updates rather than local data are transferred to the cloud, where the updates are sampled in terms of some heuristic rules and some aggregation algorithms are conducted to achieve effective knowledge integration.
In this way, the cloud can get an improved new global model and distributes it to each party for further tuning.
These steps may repeat several times until the accuracy of the learned model is acceptable for practical deployment.
But let’s dive a little deeper: there are so many topics to be discussed here:
How many gradients are needed for each model upgrade?
How often the parties partecipate in the training?
Is data cached or instantly trained on when generated?
Are updates aggregated and applied synchronously or asynchronously?
How to protect against a malicious user that wants to poison the model?
How to take into account the fact that the problem is heterogeneous even if we are in principle trying to collect the same “type of data”?
So, let’s dive right in!
Aggregation optimization
The goal of aggregation optimization is to improve the performance of the final global model, which is the core output in federated learning.
Let’s discuss the most common methods.
Weight-level aggregation
A typical and prevalent weight-level aggregation method called FedAvg.
The key idea of FedAvg is to aggregate these local models in a coordinate-based weight averaging manner, where the local model weights are averaged together with weighted average based on the importance of each client.
The problem with this technique is the so-called “weight divergence problem”: the weights might have a large mismatch due to the highly skewed data distribution in each distinctive client/party. Therefore, directly averaging them will degrade the accuracy of the generated global model.
The idea to fix the problem is to shuffle the weights in each DNN with special permutation matrices to give the models weight permutation invariance.
Features-level aggregation
The performance of weight-level aggregation largely depends on the selection of distance metric, which may not fully reflect the inherent feature information embedded in the neurons. In addition, the computation cost of the matching process is significantly heavy.
Instead of sharing the the updated model weights directly, participating devices extract and share features learned during local training. These features represent what the model found useful in the local data, but without revealing the raw data itself.
This gives the additional benefit of:
Enhanced Privacy: Sharing features instead of weights protects user data by not revealing the raw information used to generate them.
Communication Efficiency: Features are typically smaller than model weights, significantly reducing communication costs between devices and the server, especially for resource-constrained devices.
However, we might risk losing information as the local features of each client might not capture all the information needed to get to a strong final model.
Many of the methods I described in this section are implemented in the open source library Flower [2]. Check it out if you want to play around with it some more!
Heterogeneous federated learning
Heterogeneous federated learning aims to effectively aggregate models generated from heterogeneous environments.
The heterogeneous property could be reflected from data, models or device systems.
Let’s focus on data and system heterogeneity as they are the most interesting for the federated learning setting.
Data heterogeneity
Data heterogeneity indicates that collaborative clients might be in different situations, resulting in various data distributions. For example, the dog images collected from indoors and outdoors display highly heterogeneous data distribution.
This is not a federated learning problem per-se: that’s why we can borrow many ideas that are common in the ML space when dealing with data heterogeneity.
Multi-task learning
Multi-task learning enables learning models for multiple related tasks at the same time. The core design principle is to capture the relationship among tasks and leverage the relationship to facilitate the learning process.
In federated learning, clients with different data distributions could also be considered as a type of multi-task learning, where each task has a distinctive statistical representation.
Clustering-based methods
Clustering-based FL attempts to tackle the data heterogeneity issue via partitioning clients into different clusters, each of which conforms to a similar distribution.
System heterogeneity
System heterogeneity is a practical property in FL scenarios because different clients/parties naturally own heterogeneous hardware and memory limitation.
A key design for system acceleration is to develop different client selection strategies for avoiding the influence of latency stragglers.
Here stragglers refer to the clients with weak computing power which could slow down the overall FL process.
A simple idea cherry-picked participants according to the tradeoff between statistical and system efficiency. Specifically, we can define a "Client Statistical Utility" to measure the importance of each client, in this way we can develop a framework to actively select clients’ training samples in terms of the more informative data. [5]
Secure federated learning
There are a few ways attackers might steal privacy information from uploaded models or poison the model updates via adversarial attacks.
Let’s focus on model poison attacks as that’s the most interesting in the federated learning setting.
The goal of poison attacks is to induce the Federated learning model to output the target label specified by the adversary.
Although the aggregation process in FL can mitigate the attack to some extent, when the number of malicious clients becomes large, FL is inevitably poisoned.
In [3], researchers conducted a systematic study on local model poisoning attacks to federated learning. Based on this study, they proposed local model poisoning attacks to Byzantine robust federated learning via manipulating the local model parameters on compromised worker devices during the learning process.
By the way, I already talked about Byzantine learning systems in a previous article, check it out here:
#25 Genuinely Distributed Byzantine Machine Learning.

Table of contents Introduction. The challenges of Machine Learning Distributed Training. The ByzSGD algorithm. Closing thoughts. Introduction In one of my previous articles, I discussed distributed Machine Learning training frameworks: Today, I will dive a bit deeper into it by discussing what happens in the situation where components of a system fail and ther…
Back to the current article.
We have the following defense mechanism to prevent model poisoning.
Detection and exclusion:
Loss monitoring: the central server monitors the impact of local model updates on a validation dataset. Updates causing significant increases in loss or error rates might be flagged as malicious and excluded
Byzantine-Robust Aggregation: Even with exclusions, a few malicious updates can still cause harm. Byzantine-robust aggregation algorithms can be used to filter out outliers and tolerate a certain percentage of faulty devices
Client-Side Defense:
LeadFL [4]: This approach introduces a special regularization term during local model training. This term makes it harder for malicious actors to craft updates that significantly alter the global model.
Secure Aggregation:
Differential Privacy: Adding noise to the local model updates can make it harder for attackers to inject malicious patterns without being detected. This approach helps protect client privacy while maintaining model utility.
Secure Multi-Party Computation (SMPC): This cryptographic technique allows multiple parties to jointly compute a function without revealing their individual data. In the context of FL, SMPC can be used to securely aggregate local updates without compromising their confidentiality.
Conclusions
Federated learning offers a powerful approach to train machine learning models while preserving data privacy and security, making it a valuable tool for the modern ML engineer's toolbox.
With its ongoing development, federated learning opens up exciting possibilities for distributed and privacy-focused machine learning – further exploration by ML engineers is sure to unlock its full potential.
Let me know if you are using Federated learning on your job and how :)
Ludo