
LinkedIn Architecture for Production-Scale LLM Semantic Search
Inside the 0.6B SLM ranker and custom inference stack handling 100k+ queries per second.

TL;DR
LinkedIn recently detailed how they replaced their keyword and DLRM-based search stack with an LLM-based semantic search engine. The authors present a two-stage architecture using a GPU-accelerated exhaustive bi-encoder retriever and a 0.6B parameter Small Language Model ranker.
The standout engineering feat is how they achieved a 75x throughput increase to handle hundreds of thousands of queries per second under strict latency budgets through multi-teacher distillation, offline context summarization, model pruning, and a custom prefill-only inference stack.
Introduction
Running LLM cross-encoders for real-time search ranking is notoriously expensive. While cross-encoders provide superior query-document interaction modeling compared to bi-encoders, their inference costs scale poorly with long contexts and high request volumes. Most industrial systems still rely on compact encoder-based models or standard DLRMs for real-time ranking because frontier LLMs simply miss latency SLAs. A recent paper from LinkedIn outlines how they broke through this bottleneck for their Job and People Search products. The authors built a semantic search framework that brings cross-encoder-level reasoning into an online system handling tens of thousands of queries per second. Their approach shifts the focus from building massive rerankers to aggressively co-designing the model and the inference infrastructure.
Multi-Teacher Distillation and Hybrid Interactions
The system operates in two main stages: exhaustive retrieval and Small Language Model ranking. For retrieval, the authors bypass Approximate Nearest Neighbor indices entirely. They use a GPU-accelerated exhaustive retriever that scans billion-scale indices. This relies on an LLM-based bi-encoder trained with a mix of InfoNCE and pairwise margin loss, combined with a distance model that incorporates explicit engagement features like network proximity.
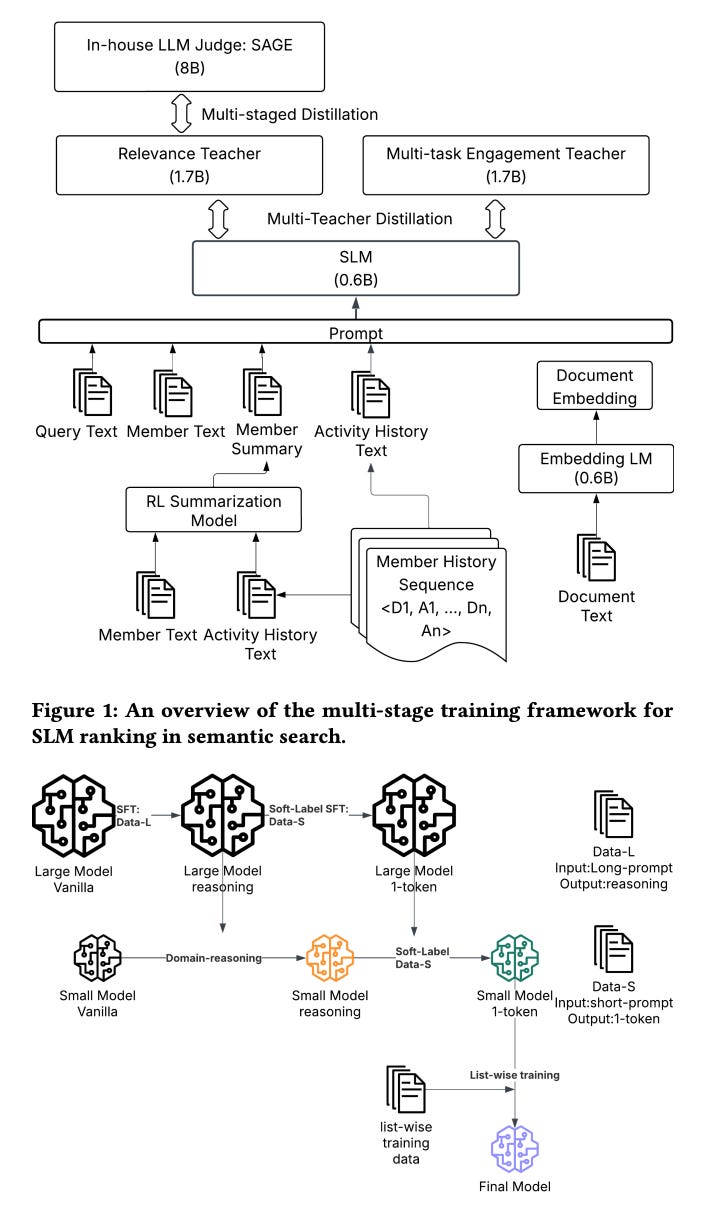
The reranking stage avoids the massive inference cost of a frontier LLM by relying on multi-teacher, multi-task distillation. The engineering team uses an 8B parameter oracle model to generate soft relevance labels and a separate 1.7B model to predict user engagement actions like clicks and applies. These teachers distill their knowledge into a unified 0.6B parameter student model.
To handle rare engagement actions in People Search, like follows or messages, the authors apply targeted loss masking. During training, they only treat a document as a negative for a specific action if another document in that same query actually received that action. This prevents the model from collapsing rare action probabilities to zero.
To fix the context length problem, they introduce a text-embedding hybrid interaction model. Instead of feeding raw document text into the ranker at inference, an offline encoder compresses documents into a small set of learned embedding tokens. The online ranker simply consumes the raw query text alongside these cached document tokens.
The Scoring-Optimized Inference Stack
The real value of this paper lies in the inference optimization stack. Deploying a 0.6B cross-encoder online usually fails when dealing with 250 documents per query. The authors solved this by recognizing that ranking is a fundamentally different workload than generation.
Because the model outputs a single scalar score from the final token logits, the team built a scoring-optimized prefill path. They stripped out iterative decoding, sampling, and per-token log-probability computations. The engine executes a single forward pass and immediately drops the KV state.
Since ranking prompts share the same long query prefix across hundreds of document candidates, recomputing the prefix is wasted compute. The authors implemented shared-prefix amortization via in-batch prefix caching and multi-item scoring masks. This ensures the query KV cache is computed exactly once and shared across the batch.
Coupled with 50 percent structured pruning of the MLP blocks and offline RL-based document summarization, these infrastructure changes yield a 75x throughput boost. By moving text-heavy processing offline and tuning the GPU engine specifically for prefill execution, this architecture proves that LLM-based cross-encoder ranking is viable in production without sacrificing the latency budgets required for consumer search.