
More Than Just a Few Tokens Deep
safety alignment that's safe also on the next tokens

TL;DR: A new paper from Princeton & Google DeepMind argues that current LLM safety alignment is "shallow," primarily affecting only the first few output tokens. This single weakness explains the effectiveness of many jailbreaks (prefilling, suffix attacks, fine-tuning). The authors propose two solutions: a data augmentation technique to "deepen" alignment and a constrained fine-tuning objective to "protect" it.
Deep dive into the paper
Current alignment methods (SFT, RLHF, DPO) often take a shortcut. Instead of fundamentally altering a model's harmful capabilities, they primarily teach it to prepend a refusal prefix (e.g., "I cannot," "I apologize") to its output for harmful queries.
The model's generative distribution for subsequent tokens remains largely unchanged from its pre-trained, unaligned state.
Evidence for Shallowness:
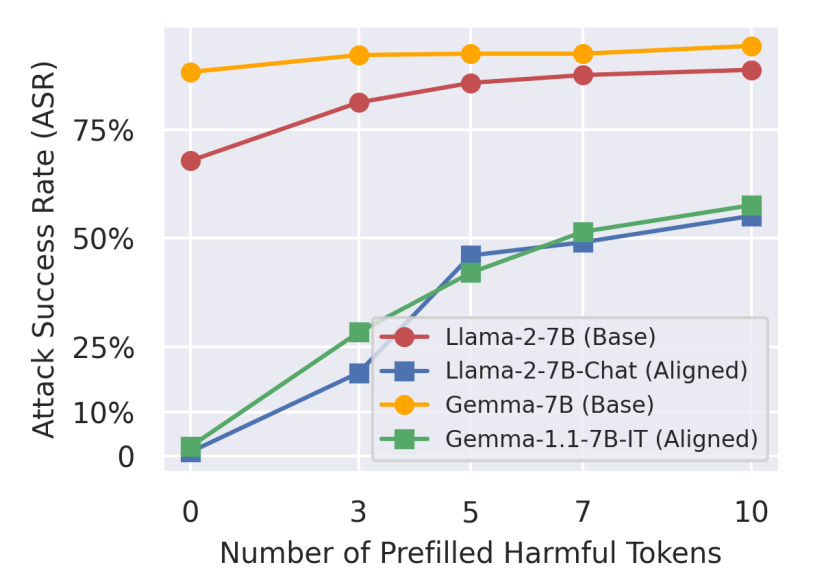
Prefilling Base Models: The authors show that simply forcing a base, unaligned model (like Llama-2-7B) to start its generation with a refusal prefix like "I cannot fulfill" makes it nearly as safe as its aligned-chat counterpart on the HEx-PHI benchmark. This suggests the refusal prefix is doing most of the safety work.
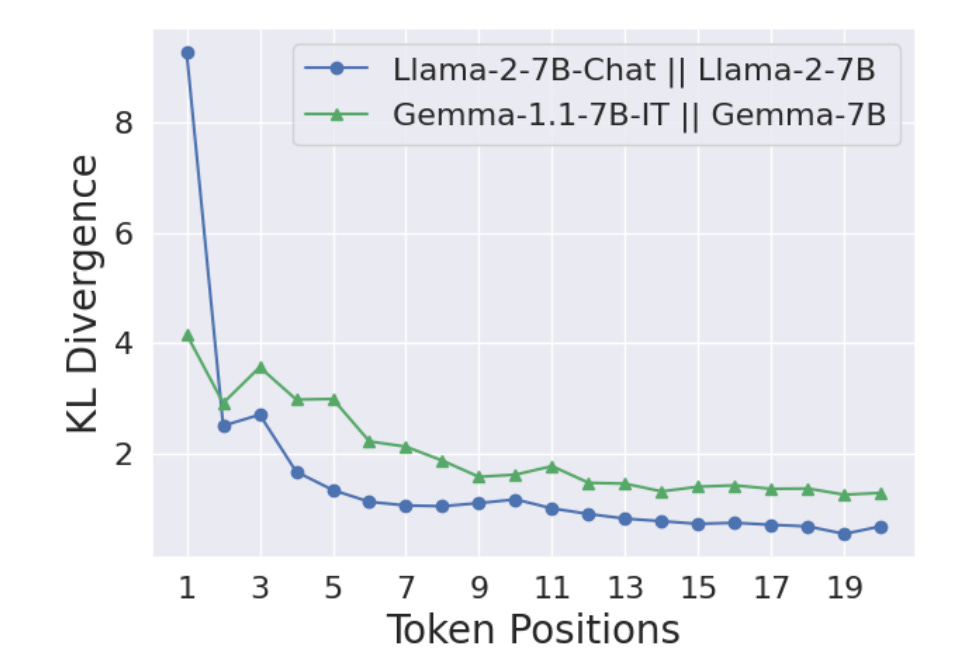
KL Divergence Analysis: By comparing the token-by-token generative distributions of aligned (π_aligned) vs. base (π_base) models on harmful prompts, they find the KL divergence is overwhelmingly concentrated in the first few tokens. After this initial prefix, the distributions become very similar again.
How This Explains Common Vulnerabilities:
This "shallow alignment" hypothesis provides an explanation for several distinct attack vectors:
Prefilling & Suffix Attacks: These attacks work by forcing the model's generation to start with an affirmative prefix (e.g., "Sure, here is..."). This bypasses the shallow safety layer and allows the model’s unaligned, helpful-but-harmful capabilities to take over.
Decoding Parameter Attacks: Using high temperature or other sampling methods increases the chance of randomly generating a non-refusal starting sequence, which then leads down a harmful generation path.
Fine-tuning Attacks: Analyzing the fine-tuning process shows that the gradients on harmful data are largest for the initial tokens. This means the shallow safety alignment is the first thing to be "unlearned," requiring very few examples and gradient steps to jailbreak the model.
Proposed Mitigations:
The paper proposes and tests two strategies to address this shallowness.
Deepening Alignment with "Safety Recovery" Data:
Method: A data augmentation technique where the model is fine-tuned on examples that start with a harmful prefix but are forced to "recover" back to a safe refusal.
Format: [INST] {harmful_prompt} [/INST] {start_of_harmful_answer} {safe_refusal_text}
Result: This trains the model to suppress harmful content even after it has started generating it, pushing the KL divergence between aligned and base models deeper into the sequence. This significantly improved robustness against inference-time attacks.
Protecting Alignment with Constrained Fine-tuning:
Method: A modified fine-tuning objective that heavily penalizes changes to the generative distribution of the first few tokens. It uses a token-wise regularization parameter (β_t) that is set high for initial tokens and low for later ones.
Objective: The loss function constrains π_θ from deviating significantly from π_aligned at the critical initial token positions.
Result: This approach reduced the success rate of fine-tuning attacks (both malicious and from benign safety regression) while maintaining comparable utility on downstream tasks. This is a practical defense for platforms offering fine-tuning-as-a-service.
My main take aways
I am no RLHF / Safety expert, but this was super insightful!
Instead of focusing only on eliciting a refusal, alignment techniques must ensure safety is robust and persistent throughout the entire generation. The concept of "alignment depth" is a critical metric, and the proposed methods are quite concrete:
Deepening Alignment: A data augmentation technique using "safety recovery" examples.
Protecting Alignment: A constrained fine-tuning objective that protects initial token probabilities.
No wonder it’s quite a famous paper!
Interesting, thanks!