
Stateful agents with Letta.ai


Introduction
In today’s article I am going to talk about how Letta developed an interface for stateful agents.
There are millions of agentic frameworks, but I feel the approach taken by Letta was different enough to discuss it.
Letta persists all state automatically in a model-agnostic representation. That means you can also move agents between model providers.
Agents are exposed as a REST API endpoints, which can be integrated into any applications.
Letta stateful agents
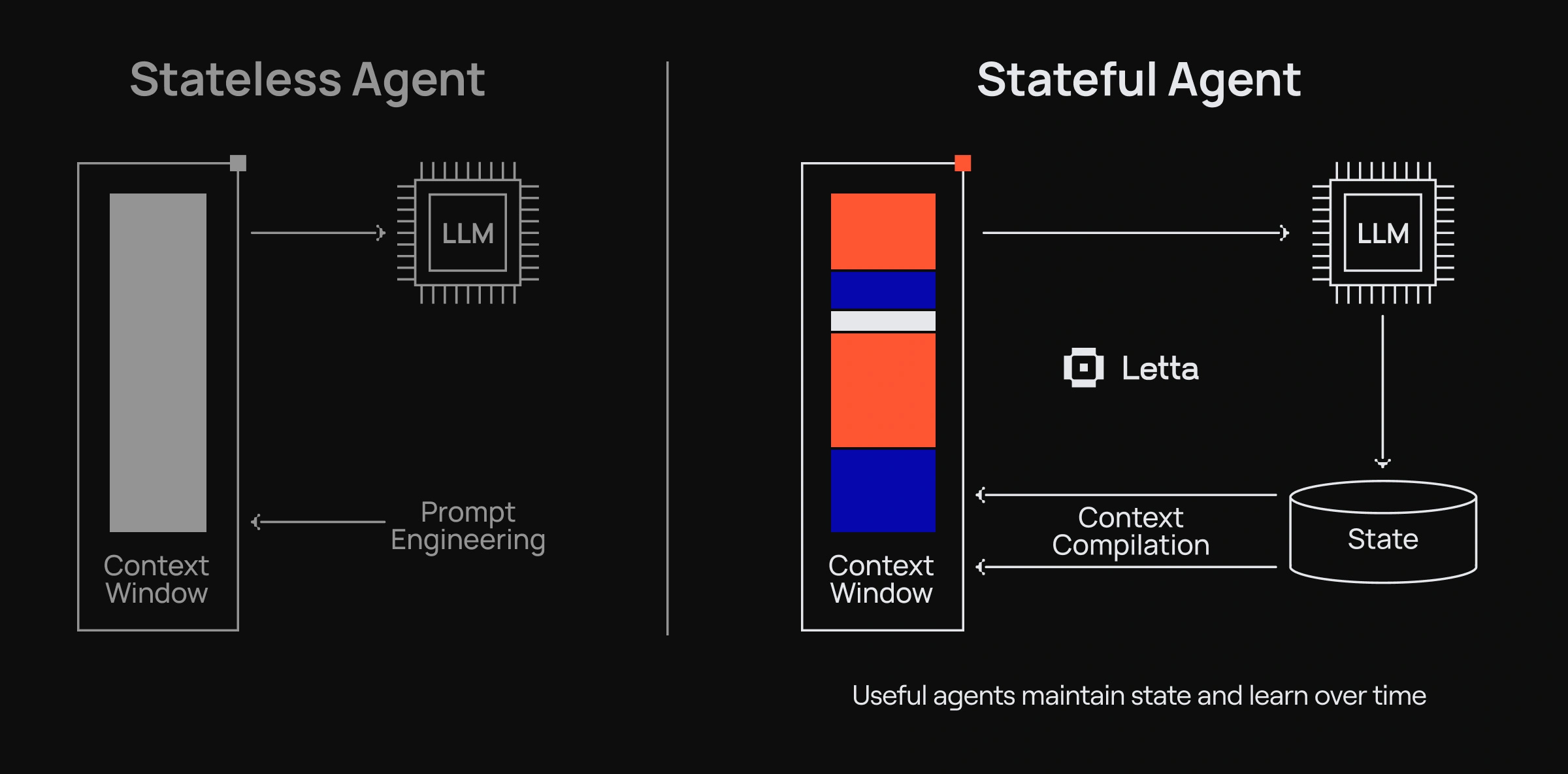
The stateless, request-response paradigm of current LLM APIs is a fundamental bottleneck for building truly autonomous agents. Operational memory is constrained to the context window: the prevalent solution—stuffing the context with RAG-retrieved data—is a crude workaround that leads to context pollution and demonstrably degrades the reasoning performance of modern models.
To move beyond stateless workflows, agents require a persistent, long-term memory system that is architected as a first-class component, not a bolt-on retrieval mechanism.
The Letta Memory Architecture: A Two-Tier System
Letta treats memory not as a single blob of text, but as a structured, two-tiered system designed to manage the trade-off between comprehensive history and context-window efficiency.
1. The External Memory Subsystem
This is the agent's persistent source of truth, designed for long-term, scalable storage. It's not a simple vector database. The external memory is a hybrid system comprising:
Semantic Store: A vector store for embedding-based search over interaction history, documents, and derived insights. This allows for fast, semantic recall of relevant experiences (e.g., "find past interactions where the user was confused about API rate limits").
Archival Store: A high-fidelity document or key-value store that holds the raw, untruncated data of all interactions, tool outputs, and ingested files. This ensures no information is ever truly lost and allows the agent to "re-examine" primary sources.
Structured State: A dedicated store for explicit memories and attributes, such as user preferences, entity graphs, and synthesized facts. This is state that has been explicitly committed to memory by the agent itself.
This entire subsystem is queryable and managed by Letta, serving as the persistent backbone for an agent's existence across countless interactions and sessions.
2. The In-Context Working Memory (The Scratchpad)
This is the state that gets compiled into the LLM's context window for a given inference task. Unlike naive RAG, it is not just a dump of retrieved chunks. Letta's Automated Context Management acts as a pre-inference compiler that intelligently assembles the context from multiple sources:
System Prompt: The static, read-only core instructions for the agent.
Editable Memory Blocks: The critical innovation. These are dedicated, structured sections within the prompt for learned information. Before an inference call, Letta's context manager queries the external memory subsystem to populate these blocks with the most salient information for the current task—summaries of past conversations, key user attributes, relevant facts, etc. The agent can also request updates to these blocks during its turn, creating a read/write memory loop.
Recent Message Buffer: A FIFO queue of the most recent turns in the conversation for immediate conversational coherence.
Historical Summary: A dynamically generated summary of older parts of the conversation that are not included in the recent buffer, distilled for key information to prevent semantic drift.
External Memory Metadata: Pointers or handles to large objects (e.g., files, full conversation logs) stored in the external archive. This allows the agent to know that a resource exists and can be requested via a tool call, without loading its entire contents into the context.
The API-Driven State Machine
A critical architectural decision in Letta is that all state is transparent and addressable. All components of the state architecture, from individual memory blocks to the external archival store, are exposed via stateful REST API endpoints.
This has profound implications for development and operations:
Observability and Debugging: Engineers can directly inspect an agent's memory to understand its reasoning. You can query a memory block to see exactly what "learned information" was presented to the LLM before it generated a faulty response.
External State Manipulation: A controlling system or a human operator can directly inject, modify, or delete memories via the API. This is invaluable for course-correction, fine-tuning behavior, or seeding an agent with initial knowledge.
Simplified Multi-Agent Systems: State synchronization between agents becomes a trivial API call. One agent can query the memory state of another, enabling complex, collaborative behaviors without building custom message-passing infrastructure.
Sleep time compute

Ever wish an AI agent could reflect on past conversations or study documents on its own time? What if it could distill key insights and have them ready for your next interaction, making it smarter and more context-aware without any extra effort from you?
That’s the idea behind Sleep-Time Agents.
This new feature introduces a multi-agent architecture where your main (primary) agent gets a dedicated partner that works in the background. Think of it like this: while your primary agent is handling live conversations, its sleep-time partner is busy reviewing, summarizing, and organizing information to enhance the primary agent's memory and intelligence.
That's a fundamental paradigm shift waiting to be unlocked: AI systems that don't just think reactively when prompted, but proactively deepen their understanding during what we call "sleep time" - the vast periods when they're not directly engaged with users.
This is the fundamental insight behind sleep-time compute, which represents an exciting new scaling direction for stateful AI systems: by activating deep thinking during their vast idle periods, these systems can expand the understanding and reasoning: pushing AI capabilities beyond what's possible when computation is confined only to active interactions.
How It Works: Learned Context in Memory Blocks
At the heart of this system is the concept of "learned context." A sleep-time agent takes a large amount of information—like a long chat history or an entire PDF document—and reflects on it to derive the most critical insights.
This process happens asynchronously, meaning it never slows down your real-time interactions with the primary agent. The agent simply gets smarter between conversations.
This feature shines in two key scenarios:
Smarter, Continuous Conversations:
The sleep-time agent automatically reviews your conversation history every few turns (you can configure the frequency). It summarizes the dialogue, identifies the user's personality, tracks key decisions, and updates memory blocks like human or persona. The result? An agent that remembers who you are and what you've talked about, leading to more natural and effective long-term interactions.Instant Document Expertise:
This is where it gets truly transformative. When you attach a data source (like a PDF, Word doc, or text file) to a sleep-time-enabled agent, a temporary "ephemeral" sleep-time agent is created. This special-purpose agent's only job is to read, process, and summarize the entire document into a new, dedicated Memory Block. Once finished, the ephemeral agent disappears, leaving your primary agent as an instant expert on that document's contents.