
Why a 1.2 Percent CTR Model Triggered a 42 Percent Application Crash


TalentStream is a mid-stage career marketplace company that recently completed a series C funding round to expand its reach into the Small and Medium Business (SMB) sector. They have achieved a significant milestone of 50 million monthly active users and over 10 million active job listings.
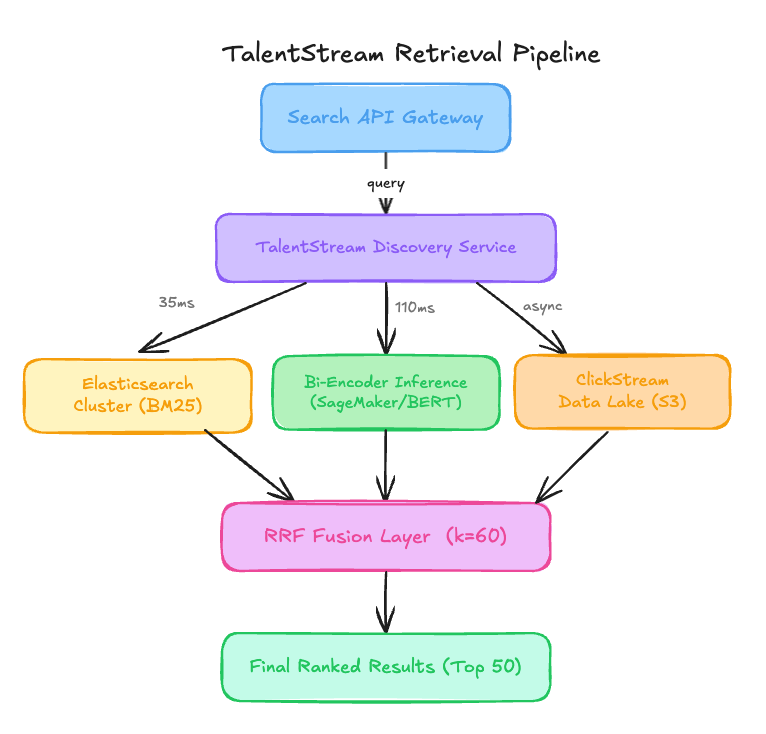
Their engineering team built a Hybrid Retrieval Engine that powers the primary job search page. Here is their setup.
Architecture Overview
When a job seeker enters a query, the system triggers a parallel retrieval flow through two distinct paths before merging the results.
Traffic patterns:
Average Throughput: 1,800 requests per second
Peak Throughput: 4,200 requests per second
Total Daily Queries: 155 million
The ML Pipeline:
The system uses a BERT-base bi-encoder fine-tuned every 14 days on the last 30 days of click-through data. The model uses Binary Cross Entropy loss, where a click is a positive label (1) and a non-click in the top 10 positions is a negative label (0).
The bi-encoder generates 768-dimensional embeddings for both the query and the job description, which are stored in a Pinecone vector database.
Current performance:
P99 Search Latency: 165ms
System Availability: 99.95%
Click-Through Rate (CTR): 1.2% (Up from 0.8% at launch)
Application Completion Rate (ACR): 1.5% (Down from 2.4% at launch)
SMB Customer Churn: 15% month-over-month increase
Costs:
Inference Infrastructure (GPU nodes): $65,000 per month
Vector Database (Pinecone): $18,000 per month
Elasticsearch Managed Service: $9,000 per month
Total: $92,000 per month
Recent incidents:
Application volume alert: Total job applications for startup-category postings dropped by 42% over a six-week period following the third model update. Recovery involved a manual roll-back to the version 1.0 base model, which temporarily restored volume but caused a 20% drop in CTR.
The Analysis
Now let me show you what is actually happening here.
Critical Issue #1: Engagement Signal Laundering
The architecture overview shows a glaring divergence: CTR is up 50% while Application Completion Rate (ACR) has plummeted by 37.5%. The model is being trained exclusively on clicks. In the job market, a click is a measure of brand curiosity or prestige, not suitability. By fine-tuning the bi-encoder on click data, the team has inadvertently created a Prestige Ranker. The bi-encoder has learned that the embedding for Google or Netflix should be close to almost every query, regardless of the job title. This is why SMB churn is spiking; their jobs are being pushed to page five because they lack the click-magnet status of a Fortune 500 company.
Critical Issue #2: The Reciprocal Rank Fusion Deadlock
In the architecture overview, the RRF Fusion Layer uses a k-factor of 60 to merge BM25 and Bi-Encoder results. However, because the Bi-Encoder is fine-tuned on the output of the previous system’s clicks, the two branches are no longer independent. The Bi-Encoder has effectively memorized the BM25 results for popular companies. Instead of a hybrid system where semantic search rescues keyword search, you have two models agreeing on the same biased results. The 110ms latency for the Bi-Encoder is becoming a tax paid for zero marginal gain in diversity.
Critical Issue #3: Negative Sampling Bias in the Top 10
The ML Pipeline description notes that negative samples are pulled from non-clicks in the top 10 positions. This is a classic feedback loop error. If the model previously ranked a highly relevant but low-prestige startup at position 8 and the user skipped it to click on a high-prestige company at position 2, the model now explicitly learns to treat that relevant startup job as a negative signal. You are actively training your model to suppress relevant small-business results because they cannot compete with the dopamine hit of a recognizable logo.
Critical Issue #4: Prohibitive Inference Costs for a Redundant Signal
The team is spending $65,000 per month on GPU nodes to run a BERT-base bi-encoder that is currently destroying the SMB revenue stream. The architecture shows that the Bi-Encoder is the primary bottleneck for p99 latency (110ms). Given that the model has collapsed into a prestige-based popularity ranker, TalentStream is effectively paying $780,000 a year to implement a feature that could be replaced by a simple SQL ORDER BY brand_prestige_score DESC.
Critical Issue #5: Feedback Loop Corruption via Periodic Retraining
The 14-day retraining cycle on a rolling 30-day window is the mechanism of the collapse. Each cycle reinforces the bias of the previous one. The Architecture Overview mentions that startup job applications fell off a cliff after the third cycle. This is the exact amount of time needed for the bi-encoder to fully “forget” the semantic meaning of job descriptions in favor of the high-variance click signals of the previous two models.
WHAT I’D DO INSTEAD
I write about ML systems in production — the tradeoffs, the architecture decisions, the stuff that doesn’t make it into papers. If you want to go deeper, the paid tier covers the technical details I can’t fit in free posts.
