
The Industrialization of Algorithm Design: AI-Driven Research for Systems

TL;DR
UC Berkeley researchers have demonstrated that LLM-driven feedback loops can autonomously design system algorithms (routing, scheduling, load balancing) that outperform human-designed state-of-the-art.
This approach, termed AI-Driven Research for Systems (ADRS), works because systems problems have reliable verifiers (simulators). The result is a shift from engineers designing heuristics to engineers designing evaluation harnesses, achieving 5x runtime improvements and significant cost reductions.
Introduction
Most of us currently use LLMs as force multipliers for implementation—essentially extremely capable autocomplete. We define the logic; the model writes the syntax. A new paper from UC Berkeley, “Barbarians at the Gate,” argues that this relationship is backwards, particularly for systems engineering.
The authors propose that AI is ready to handle the algorithm design itself.
We are talking about novel heuristics for complex, noisy environments: multi-region cloud scheduling, load balancing for Mixture-of-Experts (MoE) inference, and database query optimization.
The premise is that computer systems research involves distinct stages:
problem formulation
solution design
evaluation
While formulation remains human-centric, the design-evaluate loop is ripe for automation. This methodology, dubbed AI-Driven Research for Systems (ADRS), treats code generation not as a one-shot task but as an evolutionary search process.
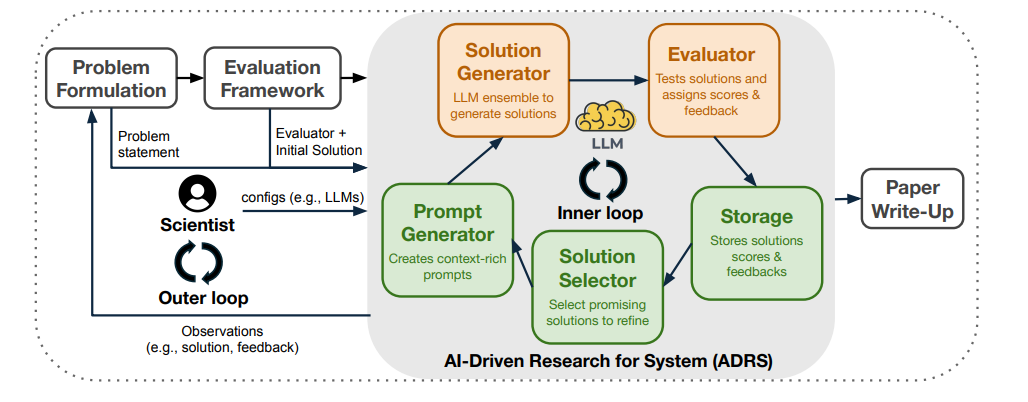
The ADRS Architecture
The core insight of the paper is that systems problems are uniquely suited for AI solutions because they admit “reliable verifiers.” Unlike generating prose or UI code, where “correctness” is subjective, a network routing protocol is either faster or it isn’t. You can measure it.
ADRS formalizes this into a closed loop consisting of five components:
1. Prompt Generator: Injects the problem context, constraints (e.g., latency SLOs), and the current best-known solution code into the context window.
2. Solution Generator: An LLM suggests a mutation to the code or a completely new algorithm.
3. Evaluator: This is the critical piece. The generated code is compiled and run against a simulator or a testbed with predefined workloads (traces). It returns hard metrics: throughput, tail latency, or distinct error types.
4. Storage: A database of solutions, scores, and execution logs.
5. Solution Selector: An evolutionary strategy (like MAP-Elites or simple greedy selection) that decides which solutions are worth keeping and mutating in the next generation.
This is effectively a genetic algorithm where the mutation operator is an LLM and the fitness function is a system simulator. The LLM doesn’t need to “know” the optimal scheduling policy; it just needs to propose a diverse set of plausible policies. The Evaluator kills the hallucinations and verifies the breakthroughs.
Production Implications
Performance vs. Cost
In a load-balancing task for MoE models, the AI-discovered algorithm rebalanced experts across GPUs 5.0x faster than the best-known baseline. For spot instance scheduling, it found a solution with 30% greater cost savings than the human expert baseline.
Crucially, these solutions were found in a few hours of unsupervised runtime. Compare that to the weeks of engineering time usually required to optimize a custom scheduler.
Interpretability
A major concern with “AI-designed” systems is usually the black-box nature of neural networks. However, ADRS outputs code (Python/C++), not weights. You can audit the logic. The generated solutions are essentially highly optimized heuristics that humans theoretically could have written but didn’t have the time or compute to explore.
The Shift in Engineering Workflow
If this approach scales, our role shifts from “Solver” to “Verifier.” The engineering challenge moves from designing the heuristic to designing the simulator. If your simulator does not faithfully represent production noise, the AI will overfit to the simulator (reward hacking).
However, for domains with high-fidelity simulators—such as packet switching, cache replacement policies, or database query planning—ADRS suggests we should stop writing algorithms by hand. Instead, we should build robust evaluation harnesses and let the model grind out the optimal logic.
For building this infrastructure yourself, OpenEvolve, ShinkaEvolve, and CodeEvolve are the leading open-source frameworks that implement the full LLM-in-the-loop evolutionary optimization pipeline for automated algorithm discovery. On the commercial side, Google Cloud offers AlphaEvolve in private preview I believe.