
The Modern LLM Optimization Stack: A Field Guide

TL;DR
Gauri Gupta’s recent compilation [1] of optimization notes serves as a comprehensive map of the current distributed training and inference landscape.
The central theme is clear: naive implementations hit memory walls immediately.
The industry has moved to complex parallelism (Tensor, Pipeline, Context) and aggressive memory management (Flash Attention, ZeRO) to scale beyond single-device constraints. It is a cheat sheet for the transition from model design to system engineering.
Introduction
Training and deploying Large Language Models has shifted from a modeling challenge to a systems engineering challenge. If you are working with 7B+ parameter models, you simply cannot fit the weights, optimizer states, and gradients into VRAM without specialized strategies.
Gupta’s notes provide a snapshot of the techniques that define the current hiring bar for ML infrastructure roles. It aggregates the tribal knowledge often locked behind the closed doors of major research labs—specifically, how to maximize GPU utilization when the model is orders of magnitude larger than a single accelerator’s memory.
The discussion isn’t just about making things faster; it is about making training possible at all.
The Mechanics of Scale
The notes break down optimization into three critical bottlenecks: Memory, Compute, and Communications.
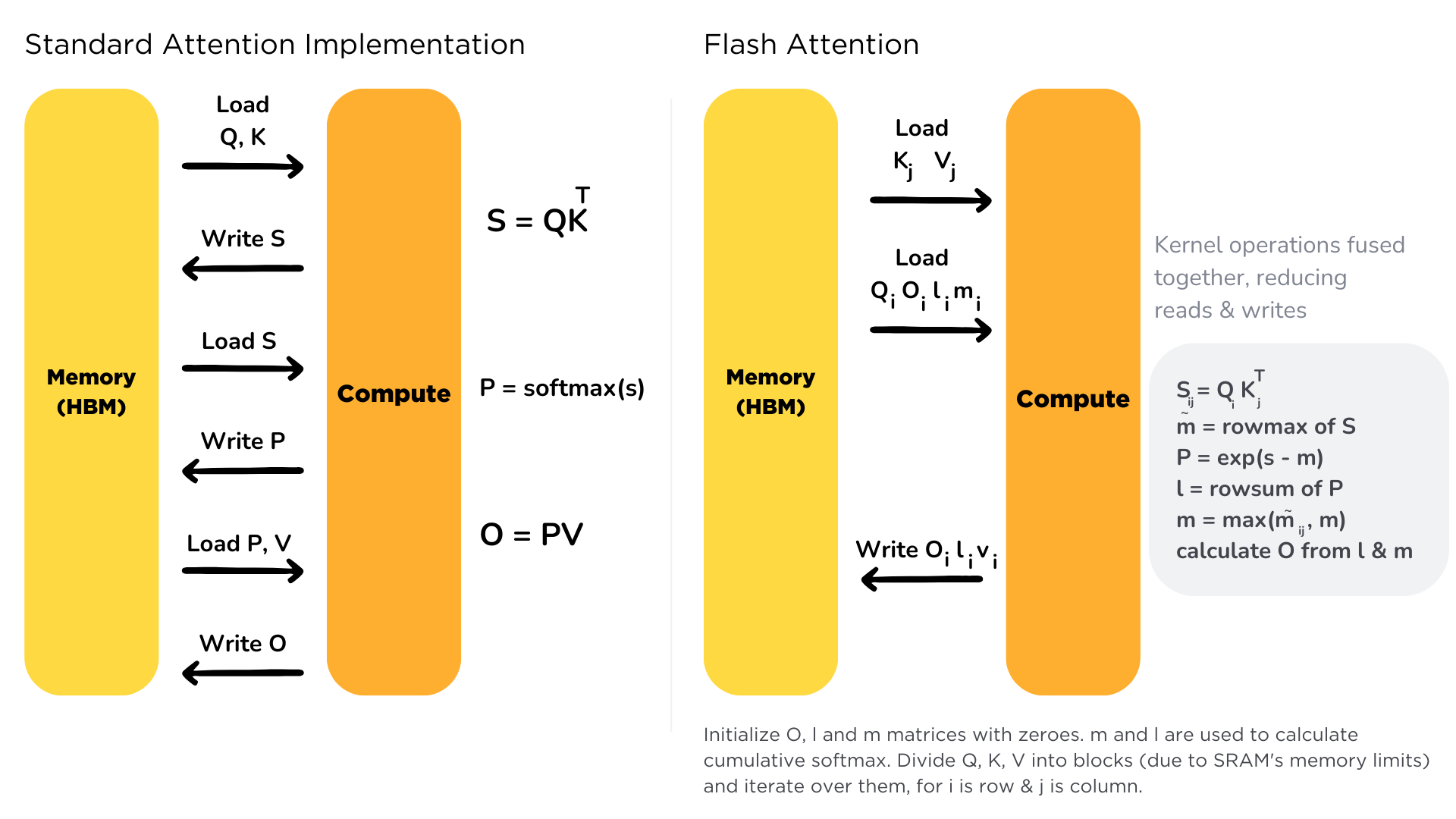
First, the memory bottleneck in Attention.
Standard attention scales quadratically. Gupta highlights Flash Attention, which addresses this by restructuring the I/O operations
By using tiling (decomposing inputs to fit in SRAM) and recomputation (storing normalization factors rather than the full N x N matrix), it reduces memory access overhead. This is the bedrock of modern long-context models.
Second, the compilation dives deep into the “Parallelism Zoo.” When a model doesn’t fit on a GPU, you have options, but each comes with a tax:
Data Parallelism (ZeRO) is the starting point. Instead of replicating the full model on every GPU, ZeRO stages 1, 2, and 3 partition the optimizer states, gradients, and finally the parameters themselves across the cluster. This allows for linear memory reduction with the number of GPUs, but increases communication volume.
Tensor Parallelism (Megatron-style) slices the individual matrix multiplications. As the notes describe, this requires splitting weight matrices column-wise or row-wise and using all-reduce operations to aggregate results after every layer. This is high-bandwidth intensive and typically confined to GPUs within the same node (NVLink).
Pipeline Parallelism addresses the inter-node scale. The model is chopped into layers, and different devices process different stages. The engineering challenge here is the “bubble”: the idle time where GPUs wait for data to flow through the pipeline. Techniques like 1F1B (One Forward, One Backward) and the newer Zero Bubble approaches attempt to interleave operations to minimize this idle time.
Finally, inference optimization relies heavily on KV Caching. The article details how we have moved beyond simple caching to Grouped Query Attention (GQA) and paging mechanisms to keep the cache memory footprint manageable during high-throughput generation.
Impact on production systems
This compilation underscores a shift in where engineering effort is best spent.
Hardware Utilization is the Primary Metric.
The detailed breakdown of pipeline bubbles and communication primitives (Ring All-Reduce) highlights that buying H100s is useless if your interconnect topology bottlenecks them.
Engineers must now model the communication-to-compute ratio.
For example, the notes on DeepSeek-V3’s DualPipe suggest that overlapping computation and communication is no longer optional, it is a requirement for training efficiency.
Inference Economics are Memory-Bound.
The section on quantization and KV caching confirms that inference cost is dominated by memory bandwidth, not just FLOPs.
Techniques like Speculative Decoding are highlighted not just for speed, but for changing the memory-access patterns.
Trading “cheap” compute from a draft model to avoid the memory bandwidth penalty of the large model. If you aren’t optimizing your KV cache eviction and using mixed-precision (or aggressive int8/fp4 quantization), you are overpaying for inference.
Complexity has moved to the Scheduler.
With Mixture of Experts (MoE) and complex pipeline schedules, the complexity of the system has migrated from the neural network architecture to the routing and scheduling logic.
As noted in the load balancing section for MoE, if the router isn’t balanced, you end up with straggler experts that drag down the performance of the entire cluster.
The shift from modeling challenge to systems engineering challenge is where things get interesting. Most people building on top of these models never touch the optimization stack, but it shows up indirectly in cost and latency.
Flash Attention and ZeRO are useful framing for understanding why inference costs stay sticky even as raw compute prices drop. Still feels like this complexity mostly lives at labs and large enterprises. Curious where you see the 'you need to care about this' threshold sitting for production builders who aren't running their own infra.