
The RL Training Recipe: When Post-Training Actually Works

TLDR
A new paper from CMU dissects the interplay between pre-training, mid-training, and reinforcement learning in reasoning models. The key findings: RL only produces genuine capability gains when targeting tasks at the model’s “edge of competence”, hard enough to be challenging but not so hard the model has zero success. Contextual generalization requires minimal (≥1%) pre-training exposure to new domains, after which RL can amplify. Mid-training emerges as a powerful but underexplored lever, outperforming RL-only approaches by +10.8% on out-of-distribution tasks. Process rewards reduce reward hacking and improve reasoning fidelity.
Introduction
Does reinforcement learning actually extend a model’s reasoning ability, or does it just sharpen what’s already there?
The literature has been surprisingly divided on this question. Some papers argue RL is merely a “capability refiner” while others show substantial reasoning gains beyond pre-training.
The problem? Prior analyses rely on uncontrolled training environments. Modern LLMs are pre-trained on massive, opaque internet corpora whose composition is fundamentally unknown. We can’t ascertain which reasoning primitives the base model has already internalized, making it impossible to isolate what post-training actually contributes.
When Does Post-Training Incentivize Reasoning Beyond the Base Model?
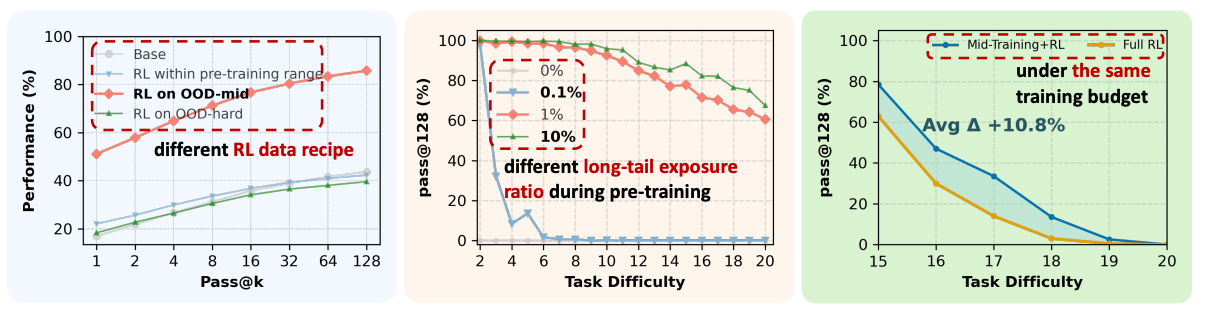
The researchers trained a 100M parameter Qwen2.5-style model on synthetic math problems with controlled complexity (measured by number of arithmetic operations). They defined three difficulty regimes: In-Distribution (ID) problems within the pre-training range, OOD-edge problems just beyond this range where the base model retains non-zero pass@128 accuracy, and OOD-hard problems substantially beyond pre-training where the base model shows near-zero accuracy.
The critical finding: For in-distribution tasks, RL improved pass@1 but showed zero improvement on pass@128 regardless of RL data regime. This means RL only sharpened existing capabilities without extending them. However, for OOD tasks, RL consistently improved pass@128 performance, but only when the RL data targeted the model’s “edge of competence.”
Training on data that was too easy (in-distribution) or too hard failed to produce genuine capability gains. The sweet spot was tasks where the model fails at pass@1 but succeeds at pass@k: difficult but not impossible.
This reconciles the conflicting views in the literature. Papers claiming RL doesn’t improve reasoning evaluated on in-domain tasks already covered during pre-training. Papers showing gains used synthetic tasks with little pre-training coverage. Both are correct; they’re just measuring different regimes.
Practical takeaway: Design RL data around the model’s edge of competence. Filter for tasks where the model fails at pass@1 but succeeds at pass@k. This avoids redundancy on easy tasks while preventing reward sparsity on impossible ones.
How Does Pre-training Exposure Shape Post-Training Generalization?
Can RL transfer reasoning skills to entirely new contexts? The researchers tested this by varying pre-training exposure to a “long-tail” context (context B) while keeping RL data fixed at 50% context A + 50% context B.
The result: When pre-training included 0% or 0.1% exposure to context B, RL completely failed to transfer. But with just 1% exposure, RL successfully generalized even to the hardest tasks (op=20), achieving up to +60% pass@128.
RL cannot synthesize capabilities from nothing. It requires latent “seeds” to amplify. But these seeds need not be complex. Even atomic reasoning primitives (op=2 examples) at sparse density provide sufficient foundation for RL to compose into complex out-of-distribution solutions.
Practical takeaway: Seed long-tail primitives in pre-training to unlock RL potential. Prioritize broad coverage of basic domain knowledge, rules, and skills at ≈1% density rather than striving for complex data samples. Once fundamental primitives are established, RL acts as a compositor, combining them to solve complex problems.
How Does Mid-Training Interact with Post-Training?
Mid-training, an intermediate phase between pre-training and post-training, has emerged as a key component of modern pipelines. But how does it interact with RL under fixed compute budgets?
The researchers compared five configurations: full mid-training, full RL, and three mixing strategies (light-RL at 20%, medium-RL at 50%, heavy-RL at 80% of compute allocated to RL).
The findings reveal a task-dependent tradeoff:
For OOD-edge tasks (slightly beyond training distribution), configurations with full mid-training and light RL outperformed heavy or full RL, with light RL achieving the best pass@1.
For OOD-hard tasks (substantially beyond training), heavy RL allocation substantially improved performance on the hardest instances in both pass@1 and pass@128.
Mid-training installs the priors that RL can exploit. This explains why models like Qwen respond more effectively to RL than architectures like LLaMA: the presence of reasoning-oriented mid-training substantially increases RL readiness.
Practical takeaway: Allocate compute in a task-aware manner. For reliability on similar tasks, allocate majority compute to mid-training with light RL. For exploration on complex OOD tasks, use modest mid-training (sufficient to establish priors) and spend heavy compute on RL exploration.
Mitigating Reward Hacking via Process Supervision in Outcome Rewards
Outcome-based rewards are effective but vulnerable to reward hacking, where models achieve correct answers through invalid reasoning chains. Can process-aware supervision help?
The researchers tested composite reward functions blending outcome rewards (correct final answer) with process verification rewards (correctness of each reasoning step).
The results: Integrating process verification improved pass@1 by 4-5% on extrapolative settings. Moderate mixes (20% outcome + 80% process) achieved the best balance. The strict reward (outcome only if process is fully correct) provided substantial improvements.
Analysis of error patterns showed process verification shifts models away from shortcut exploitation toward structurally faithful reasoning, reducing dependency mismatches and missing nodes in the reasoning graph.
Practical takeaway: Combine sparse outcome signals with dense process-level feedback. Provided process supervision is high quality, incorporating it into the reward function mitigates reward hacking and consistently improves performance.
Excellent analysis! The 'edge of competence' finding is so insightful. It trully clarifies RL's magic.