
The Unreasonable Effectiveness of Normalization: From Dual PatchNorm to nGPT

TLDR: We often obsess over attention mechanisms and context windows, but two papers suggest that normalization is the actual bottleneck for training speed and stability. First, Dual PatchNorm shows that a trivial 2-line code change (sandwiching embeddings in LayerNorms) resolves massive training instabilities in ViTs.
Second, NVIDIA’s new nGPT proposes normalizing everything (weights, states, embeddings) to the unit hypersphere, accelerating training convergence by a staggering 4x to 20x.
Normalization in LLMs
For years, the “Transformer recipe” has been relatively static. We moved from Post-LN (original Attention paper) to Pre-LN (GPT-2/3) to stabilize training, and eventually replaced LayerNorm with RMSNorm (Llama) for computational efficiency.
However, we rarely question why the gradient flow requires these specific bandages. We treat normalization as a utility to prevent exploding gradients, rather than a core geometric property of the model.
Two papers—one focusing on a “trivial” fix and one proposing a radical architectural shift—demonstrate that we have been underestimating the power of controlling vector norms.
The “Small” Fix: Dual PatchNorm (DPN)
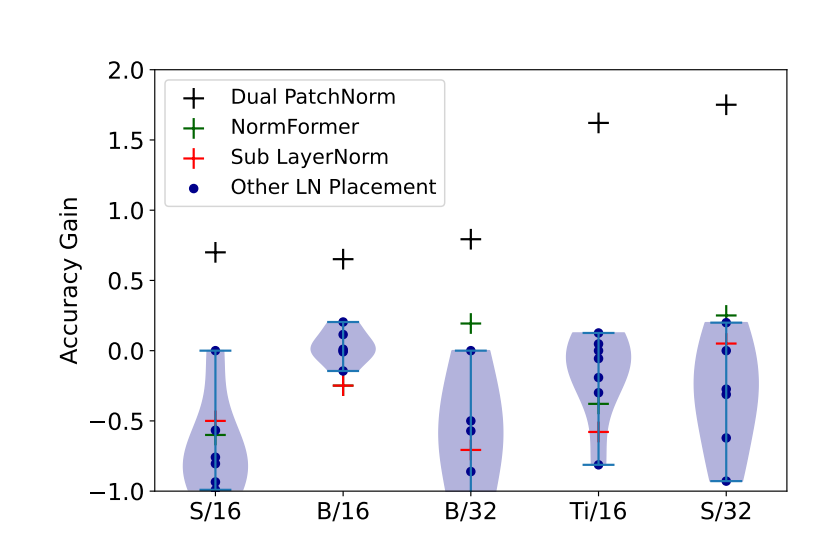
The first insight comes from Google Research. In their paper on Dual PatchNorm, they explored a persistent issue in Vision Transformers (ViTs): training instability often stems from the very first layer—the patch embedding.
They discovered that the gradient norm of the embedding layer is often disproportionately large compared to the rest of the network. The solution? Sandwich the embedding layer in Normalization.
As a twitter noted:
“I don’t know why this has not become a standard practice, but placing a LayerNorm/RMSNorm right after (tok_embed + pos_embed) resolves so much of Transformer’s training instabilities.”
The Recipe (DPN):
Instead of the standard x = PatchEmbed(x), DPN does this:
codePython
# The Dual PatchNorm “Sandwich”
x = LayerNorm(x) # LN Before
x = PatchEmbed(x) # Projection
x = LayerNorm(x) # LN AfterWhy it matters:
Gradient Scaling: It drastically scales down the gradient norms of the embedding layer, bringing them in line with deeper layers.
Performance: It outperforms exhaustive architecture searches (like NormFormer or Sub-LN) and improves accuracy across ImageNet and downstream tasks.
Simplicity: It requires no additional hyperparameters and adds negligible compute overhead.
While DPN focuses on Vision Transformers, the lesson is universal: uncontrolled norms at the entry point of the model are a primary source of instability.
The “Big” Shift: nGPT (Normalized Transformer)
Released just recently, the nGPT paper asks: What if we stop using normalization as a patch and make it the fundamental rule of the universe?
In standard Transformers, as a token passes through layers, the magnitude (norm) of its vector can grow or shrink uncontrollably. The optimizer (Adam) has to work hard to adjust effective learning rates to compensate for these shifting scales.
The nGPT Solution: Representation Learning on the Hypersphere.
In nGPT, everything is normalized.
All vectors (embeddings, hidden states) have a unit norm of 1.
All weight matrices are normalized.
Matrix multiplication becomes strictly cosine similarity.
There is no “LayerNorm” or “RMSNorm” layer because the network is the normalization.
How it works:
The input token travels on the surface of a hypersphere. Each layer (Attention and MLP) calculates a displacement vector that pulls the token toward its target on that sphere. Instead of standard weights, the model learns “eigen learning rates”—parameters that control how much the hidden state moves toward the prediction of the next layer.
The Results are Wild:
Because the optimizer no longer has to fight against varying vector magnitudes, nGPT learns significantly faster.
4x to 20x speedup in convergence (depending on context length).
It achieves the same validation loss in 20k steps that a standard GPT takes 200k steps to reach.
It renders weight decay and learning rate warmup largely unnecessary.
The Takeaway
There is a clear through-line between Dual PatchNorm and nGPT.
DPN showed us that simply constraining the input (embedding) norms fixes instability. nGPT takes that logic to its conclusion: if you constrain all norms, you don’t just fix instability—you unlock massive efficiency gains.
As we look to train larger models on longer contexts, the bottleneck may not be compute, but optimization curvature. By forcing the model to learn on a hypersphere, we turn a rugged optimization landscape into a smooth path, proving that sometimes the best way to speed up a model is to put it in a straitjacket.
i have one question, is this valid for transformer like architecture or we can use with other architecture as well, for instance i was training 2 tower model and saw user tower and item tower has large embedding gradients its expected behaviour and therefore we use adagrad because of sparse gradient update, i was thinking whether adding batchnorm after embedding and optimizing the gradient using adam will it work? what do you think?