
Titans: Google’s New Architecture That "Learns" to Memorize at Test Time
How a new Neural Long-Term Memory module unlocks 2M+ token context windows better than Transformers and Mamba.

TL;DR:
The Problem: Transformers have perfect recall but quadratic costs. Linear RNNs (like Mamba) are fast but struggle to compress complex history into a fixed state.
The Solution: Google Research introduces Titans, a family of architectures using a new “Neural Long-Term Memory” module.
The Core Innovation: Instead of a static hidden state, the memory is a deep neural network that updates its own weights at test time based on how “surprising” the data is (using gradients).
The Result: Titans scale to 2M+ context windows, achieving higher accuracy on Needle-in-a-Haystack tasks than GPT-4 and Llama-3-RAG, while maintaining fast inference.
The Memory Bottleneck
For the last few years, we have been oscillating between two poles: the Transformer (perfect recall, terrible scaling) and the Linear RNN/SSM (perfect scaling, “lossy” compression).
Linear Recurrent models (like Mamba or RWKV) try to compress the entire history of a conversation into a fixed-size matrix or vector. But as the paper argues, a simple linear compression often fails to capture complex, long-term dependencies. You cannot losslessly zip 1 million tokens into a small state vector.
Google’s new paper, Titans: Learning to Memorize at Test Time, proposes a biological analogy:
Attention is Short-Term Memory (limited capacity, high fidelity).
Neural Memory is Long-Term Memory (high capacity, stores abstractions).
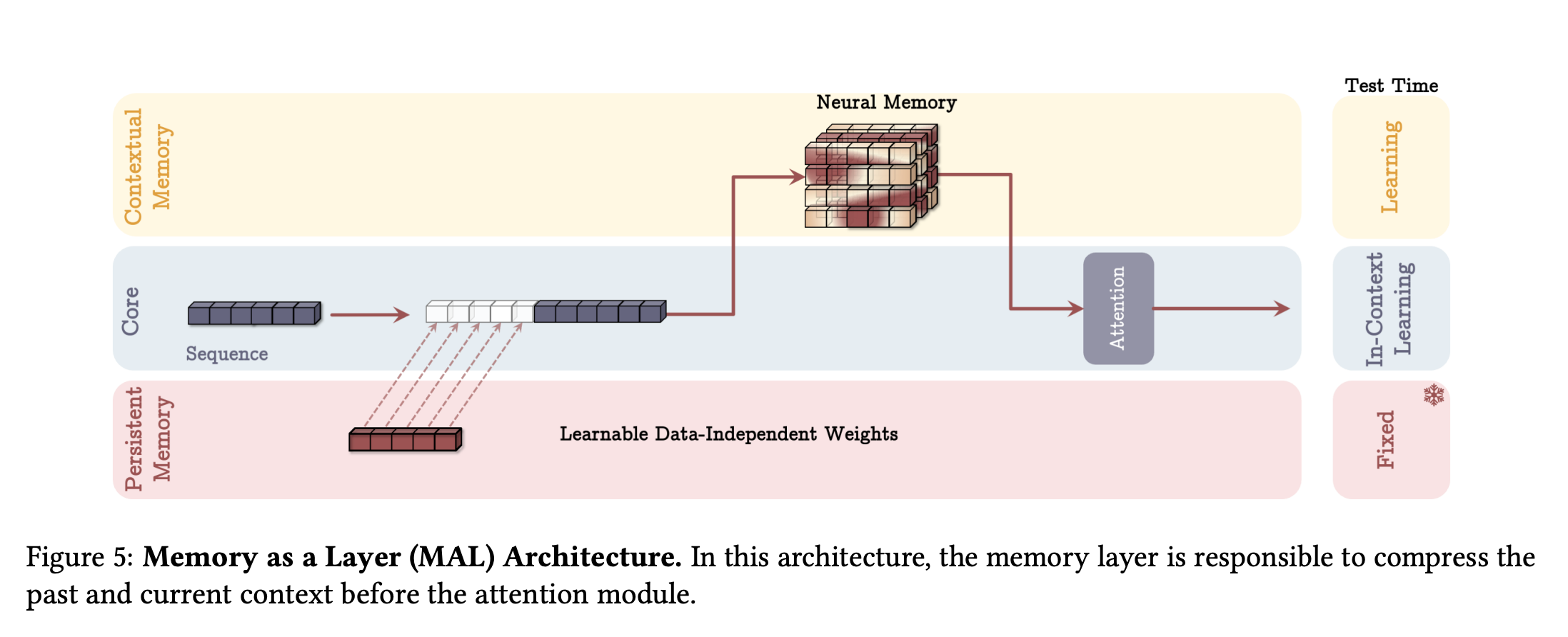
How Titans Work: Memory as a Meta-Learner
The most fascinating part of Titans is the Neural Long-Term Memory (LMM) module.
In standard RNNs, the “memory” is just a hidden state vector updated by a fixed function. In Titans, the memory is actually a Neural Network (MLP).
Learning at Test Time: As the model processes tokens, it updates the weights of this memory MLP.
The Surprise Metric: How does it know what to memorize? It calculates the gradient of the current input against the memory. If the data is “surprising” (high gradient), the memory updates significantly. If it is expected, the memory stays stable.
Forgetting: It utilizes a weight decay mechanism that acts as a forget gate, allowing it to discard outdated information to prevent the memory weights from saturating.
The Three Variants
The paper proposes three ways to integrate this Neural Memory with standard Attention (the “Core”):
Memory as Context (MAC): The input is chunked. The Neural Memory summarizes the deep history and feeds it as a “context token” into the Attention block of the current chunk. Best for ultra-long contexts.
Memory as Gate (MAG): A parallel branch setup. One branch does Sliding Window Attention (local context), the other runs the Neural Memory (global history), combined via a gate. Best balance of speed and performance.
Memory as Layer (MAL): The classic hybrid approach. Layers of Memory stacked with layers of Attention.
Performance at Scale
The results are startling. In “Needle-in-a-Haystack” tests (retrieving specific info from huge contexts):
Mamba2 and DeltaNet performance degrades significantly as context length grows.
Titans (MAC) maintained near-perfect retrieval accuracy up to 2 million tokens.
In the BABILong benchmark, a small Titans model outperformed GPT-4 and Llama-3 (with RAG) on reasoning tasks across massive contexts.
Why This Matters
Titans represents a shift toward Test-Time Training (TTT). By allowing parts of the model architecture to update their weights during inference, we move away from static “frozen” models toward adaptive systems that get smarter the longer you talk to them.