


Introduction
You know me by now. I am always interested in new takes around software and hardware interplay for ML models. If you missed some of my previous articles on that:

In today’s article, I talk about a ZML. It’s a new open source ML framework to deploy models.
And you might ask: “Huh, yet another one? Why?”
The main competitive advantage they have is that you can deploy models on a wide variety of hardware (GPUs, TPUs, CPUs and more) and they provide a prod-ready serving stack!
All of that without having to care specifically about the underlying hardware. Pretty cool!
This means that you get support for Cross-Platform GPU out of the box for free.
At the core, they use great tech from Google like OpenXLA / PJRT and Bazel for the build system (yay open source from google!)
They claim to be x2 faster than TensorRT-LLM on a H100. Pretty impressive!
Let’s see a bit more details!
What’s the deal?
Compiling a model for a given hardware is a matter of changing a flag!
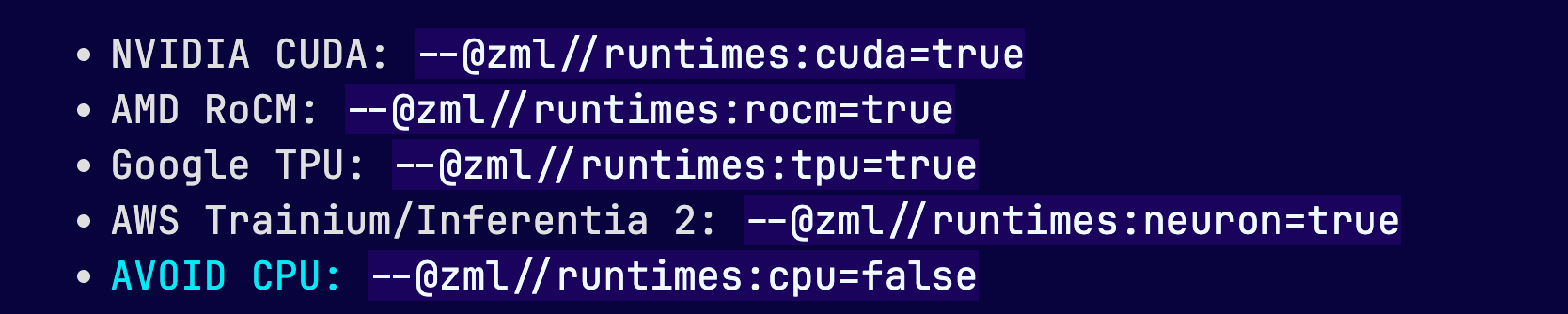
They make it really easy to both:
If you ever had to deploy a model on a specific GPU/TPU, you know the pain this solves!
ZLM leverages strong type checking thanks to Zig. In this way, you can look at the general model life cycle with different eyes:
Open the model file and read the shapes of the weights -> zml.HostBuffer (using memory mapping, no actual copies happen yet)
Instantiate a model struct -> Model struct (with zml.Tensor inside)
Compile the model struct and its forward function into an executable. foward is a Tensor -> Tensor function, executable is a zml.FnExe(Model.forward)
Load the model weights from disk, onto accelerator memory -> zml.Bufferized(Model) struct (with zml.Buffer inside)
Bind the model weights to the executable zml.ModuleExe(Model.forward)
Load some user inputs (custom struct), encode them into arrays of numbers (zml.HostBuffer), and copy them to the accelerator (zml.Buffer).
Call the executable on the user inputs. module.call accepts zml.Buffer arguments and returns zml.Buffer
Return the model output (zml.Buffer) to the host (zml.HostBuffer), decode it (custom struct) and finally return to the user.
Still, it’s very likely that you train your model using PyTorch or Jax, not ZLM. So, most likely you’d need to convert it to ZLM before you are able to use all these goodies.
In general, porting a model is hard so this step could be bug-ridden, especially as model code is not usually “SWE standard code” with shapes not outlined clearly, unusued code paths, etc.
My final thoughts
As always, there’s no free lunch. Initial progress is indeed impressive and avoiding hardware lock-in is huge at scale.
As it has just been launched, it still does not support: expert parallelism (a bit of a shame as MoE is the inference meta after all) and porting things around could make you go a little crazy!
Porting models to a new framework and learning that framework does not come for free, and you will still somewhat lock in in the framework.
Still, it’s pretty cool to see new things being built in the inference / software-hardware codesign space!