
xAI - Recommendation System deep dive [Part 2]
what changed in the May 15 update

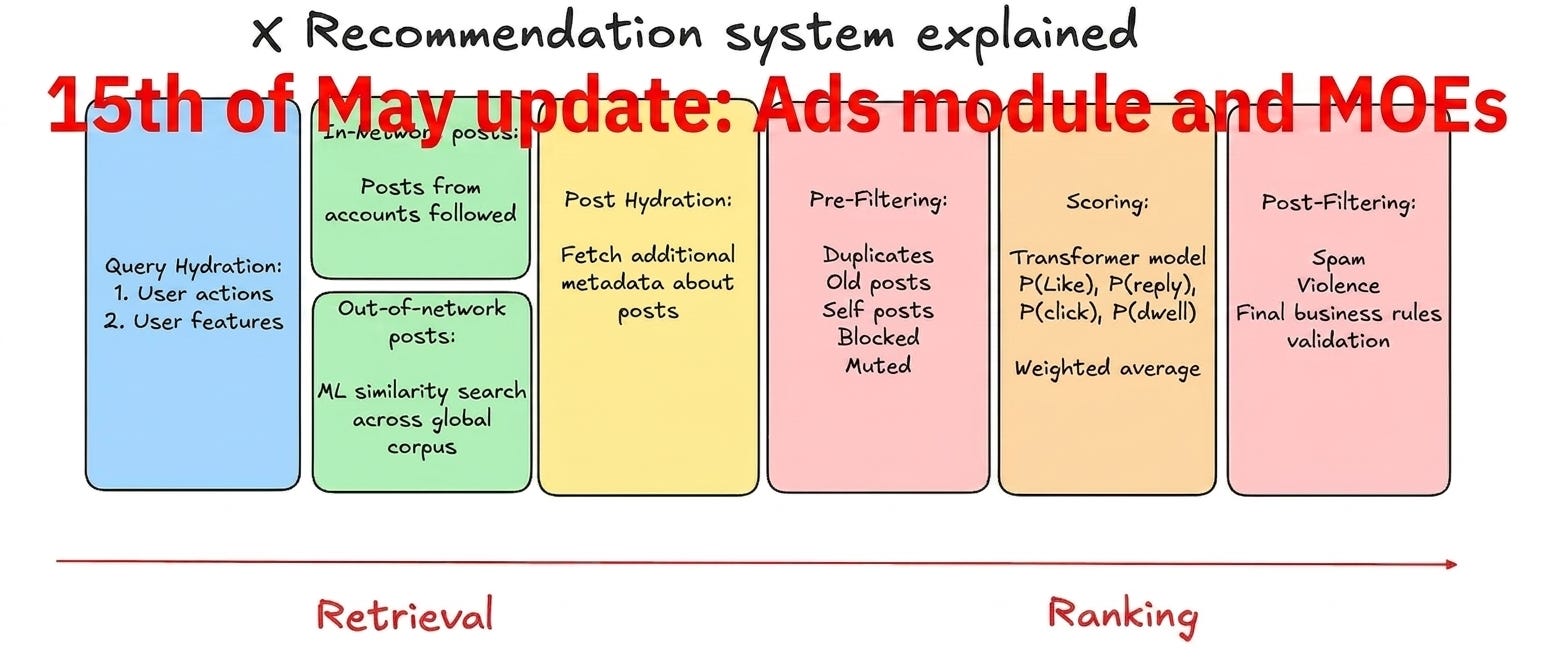
Introduction
Four months ago I wrote a deep dive on xAI’s open-sourced recommendation system. That release was a readable codebase but not a runnable one.
No model weights, two separate scripts for retrieval and ranking that you had to glue together by hand, no content understanding service, no ads logic in the public code.
On May 15, 2026, xAI shipped a new commit. 187 files changed, +18,263 lines, -926 lines.
This is Machine Learning at Scale and the May update has enough new architecture in it to deserve a follow-up deep dive.
Read all the way for my take on it :)
First things first.
If you have not read the original deep dive, start there.

This post assumes you know what Thunder is, what the two-tower retrieval does, and why candidate isolation in the attention mask matters.
Now, with that out of the way, let’s get started!
TLDR
The May update transitions the codebase from “open source dump” to “runnable system.”
There is now a single entry point phoenix/run_pipeline.py that runs retrieval and ranking together, and a pre-trained mini model is shipped as well so you can run inference end to end on your own machine.
Three subsystems that were missing in January are now public: a content understanding service (Grox), an ads blending module, and additional Phoenix retrieval clusters (one labeled MoE, one for topic-driven retrieval).
The home mixer hydrates significantly more context per request: impression bloom filters, mutual follow Jaccard scores, served history, IP, inferred topics, starter pack membership.
A second scorer file vm_ranker now sits next to the production scorer ranker scorer. Reading both reveals something important: the engineer-tuned weighted sum I assumed was gone is still alive. It is right there in ranker_scorer with 22 weighted actions.
The new vm_reranker is a gRPC-based experimental reranker that adds DPP (Determinantal Point Process) diversity on top.
In the end of this post I will give my read on what is real, what is sanitized, and what xAI is still hiding. Keep reading for that!
Unified pipeline
In the January release there were two scripts, run_retrieval.py and run_ranker.py, and running them in cascade required manual coordination and undocumented config dependencies.
The new phoenix/run_pipeline.py replaces both with a single entry point.
The code confirms the architecture:
Load retrieval model checkpoint, embedding table, and config.
Load ranker model checkpoint, embedding table, and config (separate from retrieval).
Load a pre-computed corpus of candidate representations and a user action sequence.
Hash the user history into embedding lookup indices (multiple hashes per ID).
Run the retrieval model to produce a user representation, then dot product against the corpus to get top-K candidates.
Batch the top-K through the ranker model, get per-action engagement probabilities.
Collapse to a single score with a weighted sum and rank.
Two things worth noting from the code:
The retrieval and the ranker are separate models with separate embedding tables. They share architecture (the same transformer backbone) but they are trained and exported independently. This explains why the run_pipeline script loads two model configs.
The mini-model retrieval in this script does brute-force dot product over the corpus (corpus_repr @ user_repr), not HNSW. Production almost certainly uses HNSW or similar for sub-linear ANN. The brute force version is the runnable-on-your-laptop version.
The “no light ranker between retrieval and ranking” point I made in the previous deep dive holds. The pipeline goes retrieval → ranker → weighted sum, no intermediate cull.
Pre-trained mini model
The repo now ships a working artifact.
Specs of the mini model:
256-dim embeddings
4 attention heads
2 transformer layers
~3 GB packaged size
This is a toy. Production is almost certainly an order of magnitude larger on every axis. But the toy is enough to:
Run inference end to end on a sample sports corpus they ship
Verify the candidate isolation attention mask works the way the README describes
See how hash-based embeddings are looked up at runtime
That last point is worth pausing on, because the embedding mechanism is now clear from the code.
The system uses hash-based embedding lookup. From run_pipeline.py:
raw = (ids[i] * scales[j] + biases[j]) % modulus
out[i, j] = 0 if ids[i] == 0 else int((int(raw) % (num_buckets - 1)) + 1)Linear congruential hash: multiply the ID by a per-hash-function scale, add a bias, take modulo a large prime, then map into the embedding table bucket range.
Each ID gets hashed multiple times (the config has separate user_hash_scales, item_hash_scales, author_hash_scales, each a list).
The result: a user ID becomes a small set of embedding indices, which are summed to form the user vector. Same for posts and authors.
The retrieval and ranker have separate embedding tables but the same hashing scheme.
Implication: there is no separate offline tower that produces a dense user embedding sitting in a KV store. The user representation is computed inside the model itself, from hashed inputs, on every request.
Hash trick + large embedding tables + multiple hashes to reduce collisions, much more scalable than precomputing dense vectors per user.
Grox: content understanding service
The new grox/ directory is a separate Python service. It runs in its own process (literally multiprocessing.Process) and talks to the rest of the system over data stores.
Engine architecture
Reading engine.py, the architecture is simpler than the file tree suggested:
The engine runs in a dedicated subprocess.
Inside the subprocess, an asyncio loop polls a multiprocessing task queue.
For each task, it calls a single dispatcher class: PlanMaster.exec(task).
Results go back through a response queue.
That’s it. No Kafka. No internal message bus. Just a process with a queue, an event loop, and a dispatcher.
Two auxiliary processors start up alongside the engine:
MediaProcessor: handles image processing
ASRProcessor: automatic speech recognition for video audio
They are transcribing the audio in videos so the content understanding pipeline can read what people are saying, not just look at frames.
This is the kind of capability that quietly raises the floor on what the platform can detect (misinformation in podcast clips, policy violations in voice content, etc.).
It is not mentioned in the README. It is just sitting in the code.
Strato as the data backbone
The data layer file (tweet_strato_loader.py) reveals what I had wrong before. I claimed Grox routed work through Kafka and Strato. It does not. Strato is its data store, not a message bus.
Specifically, Strato is used bidirectionally:
Input (Grox reads):
StratoContentUnderstandingMetadataV2: post metadata for a tweet ID
StratoContentUnderstandingAuthorMetadata: author metadata
StratoContentUnderstandingPostQuoteMetadata: post + quote metadata
StratoUserRecentPosts: a user’s recent post history
StratoSafetyLabel: existing safety labels
Output (Grox writes):
StratoReplyRankingScore.put: reply ranking scores
StratoReplyRankingScoreV2Kafka.insert: reply ranking scores routed through a Kafka topic
StratoReplySpamAnnotation.put: spam annotations on replies
So Strato is both Grox’s input (the content metadata it reads to classify) and its output (the labels it writes back for downstream consumers like AdsBrandSafetyHydrator to read).
Kafka shows up only as a routing layer for one specific output (ReplyRankingScoreKafka), not as the orchestration backbone.
This matters because it changes the mental model: Grox is not a streaming pipeline. It is a task-processing service with a Strato-shaped read/write contract.
Task structure
Tasks inherit from a base Task class and a TaskWithPost subclass for post-aware tasks. The pattern looks like this (from task_spam_detection.py):
python
class TaskSpamDetection(TaskWithPost):
eapi_low_follower_classifier = SpamEapiLowFollowerClassifier()
@classmethod
async def _exec_with_post(cls, ctx: TaskContext, post: Post) -> None:
res = await cls.eapi_low_follower_classifier.classify(post)
ctx.content_categories.extend(res)
# ... metrics emission with follower-bucket taggingEach task instantiates a classifier as a class-level attribute, defines _exec_with_post, and writes results into a shared TaskContext.content_categories list.
Simple, stateless, parallelizable.
One detail from TaskSpamDetection worth flagging: it explicitly targets replies, not top-level posts. It walks the reply chain (post.ancestors) and buckets by follower count of the reply target and root. Replies into accounts with under 1000 followers get extra logging. This is asymmetric protection: small accounts get more attention from the spam detector than large ones do.
A second task, TaskBangerScreen, classifies posts for “banger” potential and reveals how Grox interacts with Grok the LLM:
class TaskBangerScreen(TaskWithPost):
classifier = BangerInitialScreenClassifier()
_cached_topics = None
_cache_timestamp = None
...
res = await cls.classifier.classify(post, topics=cls._cached_topics)Three things this tells us:
“Banger” is a real classification category (ContentCategoryType.BANGER_INITIAL_SCREEN), not a filename joke. Posts get an explicit binary screen for whether they look like a banger.
The naming (”initial screen”) implies a two-stage pipeline: this is the cheap filter that runs on everything, presumably feeding a more expensive classifier downstream.
Banger detection is conditioned on topics fetched from Grok. The topics come from StratoGrokTopics(), cached at the class level with a TTL, refreshed periodically. So Grok the LLM generates a topic taxonomy, that taxonomy is stored in Strato, and Grox tasks consume it to condition their classification on what topics are currently relevant.
This is the substrate I had not seen before: Grok produces topic structure → Strato persists it → Grox classifiers use it → safety labels and content categories propagate back to the home-mixer hydrators that feed the ranker.
Grok shows up not as a ranker (which is what most public discussion assumes) but as a content-understanding co-processor that feeds the classifier layer.
The task list visible in the file tree also includes PTOS category and policy classification, reply ranking, multimodal post embedding, and Grok-based user-post-action labeling.
Why this exists
The ranker has no idea what a post is “about.” It only sees engagement sequences and hashed embeddings. That works for relevance, but it does not work for safety.
You cannot rely on a transformer trained on Like prediction to also decide what counts as spam, what counts as a PTOS violation, or what gets a sensitive content label.
So Grox sits beside the ranker.
The ranker predicts engagement, trained on user actions.
Grox classifies content, trained on labels. The two share a substrate (Strato) but have independent lifecycles, model families, and release cycles.
Ads module
In January, ads were a black box. The code referenced a “for_you_server” but there was no ads logic in the public repo. May fixes this, and the ads code is the cleanest, most readable part of the whole release.
The new home-mixer/ads/ module has two blenders with genuinely different strategies:
partition_organic_blender.rs: partitions the feed into safe and unsafe posts, places each ad between two safe posts as bookends, then distributes everything else as filler.
safe_gap_blender.rs: places ads only in positions where the natural feed order already has safe content on both sides, with controlled spacing between consecutive ads.
Plus two new hydrators:
ads_brand_safety_hydrator.rs: pulls safety labels per tweet and computes a brand safety verdict
ads_brand_safety_vf_hydrator.rs: same thing but for the visibility filter pipeline
And a new candidate source: ads_source.rs.
The key design choice: ads are not ranked by the main transformer.
They come in through their own source with their own scoring (almost certainly an ads auction model that is not in the public code), and the blender decides where they land relative to organic candidates.
This is the same pattern Meta uses for Reels ads and Google uses for YouTube ads. Organic and paid are two separate ranking systems that meet at a blender. The blender’s job is to maximize a combined objective subject to constraints (min ad load, max ad load, brand safety, advertiser adjacency controls).
How brand safety verdicts are computed
AdsBrandSafetyHydrator is the upstream component that attaches a BrandSafetyVerdict (Low / Medium / High risk) to each organic post.
Mechanism:
Collect all tweet IDs from the candidate set, including retweeted and quoted IDs.
Batch-fetch safety labels from SafetyLabelStoreClient (this store is fed upstream, almost certainly by Grox).
For retweets, use the underlying tweet’s labels via retweeted_tweet_id.
For quote tweets, take the WORST verdict between the quoting post and the quoted post.
That last point is a sharp piece of design. A clean post quoting toxic content inherits the toxic verdict. You cannot launder a brand-unsafe post by wrapping it in a quote tweet.
There is also a defensive fallback: if the safety label lookup errors out for a quoted tweet, the verdict defaults to MediumRisk. Fail-closed on quotes.
Caching is done with Moka, with TTLs that depend on tweet age:
new_tweet_ttl: 60 seconds (under 5 minutes old, labels still updating)
old_tweet_ttl: 1 hour (older, labels stable)
cache size: 1,000,000 entriesThis is the kind of cache tuning you only get from running the system in production. New tweets get short TTLs because their labels are still being computed by Grox.
Old tweets get long TTLs because their labels do not change.
How safe_gap_blender uses those verdicts
let safe_gaps = find_safe_gaps(&scored_posts);
let spacing = compute_spacing(&ads);
let placements = assign_ads_to_gaps(&safe_gaps, ads.len(), &spacing, first_ideal);
interleave_and_finalize(scored_posts, ads, &placements)find_safe_gaps is 11 lines and is the actual brand safety rule:
fn find_safe_gaps(scored_posts: &[ScoredPost]) -> Vec<usize> {
let n = scored_posts.len();
let mut safe = Vec::new();
for g in 1..n {
if has_avoid(&scored_posts[g - 1]) { continue; }
if g < n && has_avoid(&scored_posts[g]) { continue; }
safe.push(g);
}
safe
}A position is a safe gap only if neither the post immediately above nor the post immediately below is “avoid.” has_avoid returns true when the BrandSafetyVerdict is MediumRisk. That is the rule. No ad next to medium-risk content, in either direction.
compute_spacing is dynamic. It takes the first 4 ads, looks at their insert_position values, and uses the smallest gap as the requested spacing. The minimum is requested / 2 (rounded up). With fewer than 2 ads or a tiny inferred gap, it falls back to DEFAULT_SPACING { requested: 3, min: 2 }.
assign_ads_to_gaps walks the ad list and, for each ad, picks the safe gap closest to its ideal position subject to the min distance from the previous placement. The picker uses binary search via partition_point:
let min_offset = gaps.partition_point(|&g| g < min);
let candidates = &gaps[min_offset..];
let ideal_pos = candidates.partition_point(|&g| g < ideal);Two binary searches: first throw out gaps closer than min to the previous ad, then find the gap closest to ideal and tie-break on absolute distance. If no valid gap exists, return None and the blender stops placing ads early.
Brand suitability: advertiser-defined adjacency controls
There is a separate layer in util.rs that I missed in my first read. Advertisers can attach controls per ad:
A list of blocked handles (should_drop_handle): drop the ad if the post above or below is by one of these authors.
A list of blocked keywords (should_drop_keyword): drop the ad if the post above or below contains any of these keywords (tokenized properly via a TweetTokenizer).
A brand safety risk tier (should_drop_bsr_low): if the ad is tagged as BsrLow or BsrIas, drop it when adjacent to a LowRisk post.
That last one is counterintuitive at first read. Why drop a low-risk ad next to a low-risk post? It is not about safety, it is about category exclusion at the advertiser tier. BsrIas is the IAS (Integral Ad Science) brand safety certification level. Advertisers who pay for IAS verification want their ads only in very specific contexts, and the rule says: if your ad is BsrLow or BsrIas and the adjacent post is even rated LowRisk (the most lenient bucket), drop the ad rather than risk a placement that violates the advertiser’s contractual standard.
This is brand SUITABILITY (advertiser preferences) layered on top of brand SAFETY (platform-wide rules). Both are in the public code.
How partition_organic_blender is different
partition_organic_blender.rs takes a more aggressive approach. Instead of finding safe gaps in the natural order, it actively partitions the feed:
Split scored posts into safe (LowRisk) and unsafe (MediumRisk) buckets.
Compute the max number of ads as min(ads.len(), n / spacing.requested, safe_count / 2). Each ad needs two safe posts to bookend it, so safe count divided by 2 is a hard ceiling.
Chunk the safe posts into actual_ads equal-sized groups. For each ad, take the first two posts of its group as the “above” and “below” bookends.
Run the brand suitability checks (BsrLow, handle blocklist, keyword blocklist) against those bookends. Skip the ad if any check fails. Emit counters per drop reason (bsr_drop, handle_drop, keyword_drop).
Build the feed as a sequence of [above, ad, below, ...filler] triples, with leftover safe posts and all unsafe posts sorted by score and distributed evenly as filler between triples.
Standard truncate-to-RESULT_SIZE, no-ending-on-ad.
The difference matters. safe_gap_blender respects the natural feed order and only places ads where it can. partition_organic_blender rearranges the feed so every ad gets safe bookends, with unsafe content pushed into filler regions away from the ads.
Trade-offs:
Partition gives guaranteed safe-adjacency for every placed ad. Safe gap relies on the natural order having enough safe gaps.
Partition is more invasive to the ranking. The score-sorted order is preserved within filler regions but the overall structure is dictated by ad placements.
Safe gap is less disruptive to organic ranking but places fewer ads when the feed is “dirty.”
These two strategies are presumably A/B tested in production. The codebase shows both, which means xAI has not committed to one strategy globally.
Two operational details that scream production system
interleave_and_finalize truncates the feed to RESULT_SIZE, and if the last item is an ad, pops it. No feed ever ends on an ad.
Two metrics are emitted per blend (AdsBlender.post_brand_safety_verdict and AdsBlender.ad_brand_safety_risk) so they can monitor the distribution of safety verdicts and ad risk tiers in production traffic.
The blender itself is policy-free orchestration. The actual rules live in has_avoid, in the safety label store, and in the per-ad adjacency controls. That separation is the right one. You can change brand safety rules without touching the blender.
Phoenix retrieval clusters: MoE and topics
Alongside the original dense retrieval source, two new sources appeared: phoenix_moe_source.rs and phoenix_topics_source.rs.
When I first read the filenames I assumed these were three different retrieval architectures. Reading the code: they are not. They are three different parameterizations of the same retrieval client.
All three sources call the same PhoenixRetrievalClient. They differ in three things:
Cluster ID. Each source reads a different config param for its target cluster: PhoenixRetrievalInferenceClusterId, PhoenixRetrievalMOEInferenceClusterId, PhoenixRetrievalTopicInferenceClusterId. These map to separate gRPC backend deployments.
Extra arguments. The topics source passes topic_entity_ids and a topic_filter_mode to the retrieval call. The MoE source passes empty topic IDs.
Enable conditions. The MoE source enables only when the user is not making a topic request and there are no cached posts. The topics source enables only when there IS an explicit topic request, OR when the user is new and has new-user topic IDs (cold start path). The regular Phoenix source covers the default case.
So in production there are at least three Phoenix retrieval clusters running. The “MoE” cluster is presumably a Mixture of Experts model deployment, distinct from the regular dense retrieval, and the topics cluster is one tuned/trained for topic-conditioned retrieval. The home mixer just picks which cluster to call based on the query characteristics.
What the routing logic does tell us: there is at least one specialized cluster for topic-driven requests (when you click into a Topic or Community), and another (MoE) presumably tuned for diversity or specialization that the regular cluster does not provide. The exact model differences are not in the public repo.
Note also: candidates from each source are tagged with a different ServedType (ForYouPhoenixRetrieval vs ForYouPhoenixRetrievalMoe).
Downstream code can attribute outcomes to specific retrieval paths for offline analysis.
Hydrators: feature engineering in disguise
Hydrators attach context to each request and to each candidate before the model sees them. The May commit adds a long list of new hydrators. I have read two of them in detail; the others I can only name from the file tree.
Two hydrators worth understanding deeply
1. impression_bloom_filter_query_hydrator
This hydrator fetches a per-user impression history as a list of bloom filters. The pattern:
Calls ImpressionBloomFilterClient.get(user_id, SurfaceArea::HOME_TIMELINE) via Thrift.
Receives a list of bloom filter entries, each with its own size_cap and false_positive_rate.
Converts each entry into a proto for downstream consumption.
The bloom filter is how the system tracks “you have already seen this post” without storing every impression ID per user. Multiple filters per user likely correspond to different time windows (recent impressions in a tight filter, older impressions in a looser one). The size cap and false positive rate are tuned per entry, which is a tell that they have explicit memory budgets per user for impression dedup.
Note also: the surface area is hard-coded as HOME_TIMELINE. The bloom filter is surface-specific. Your impression history on the home feed is different from your impression history on the Following feed.
2. mutual_follow_jaccard_hydrator.rs
This is the most technically interesting hydrator in the new release. It estimates the Jaccard similarity between the viewer’s follow set and the candidate author’s follow set, but it does not compare the raw follow sets.
Instead, both sides have a pre-computed MinHash signature of length 256 (constant MIN_HASHES). The hydrator:
Reads the viewer’s MinHash from query.viewer_minhash (attached upstream).
Batch-fetches the MinHash for every unique candidate author from Strato.
For each candidate, compares the two 256-element signatures element-wise:
fn jaccard_from_minhash(a: &[i64], b: &[i64]) -> f64 {
let matching = a.iter().zip(b.iter()).filter(|(x, y)| x == y).count();
matching as f64 / len as f64
}The fraction of matching positions in the two MinHash arrays is an unbiased estimator of the Jaccard similarity of the original sets. MinHash-LSH is a 25-year-old technique from web search deduplication. Seeing it here, in production code, doing graph-overlap estimation for a recommendation system, is genuinely instructive.
Why this matters: storing every user’s full follow set as a sortable signature would cost gigabytes per active user. Storing a 256-element sketch costs 2 KB per user. The hydrator can batch-fetch sketches for hundreds of candidate authors per request and compute their graph overlap with the viewer in microseconds.
If you take one thing from this section: this is what production ML at scale actually looks like. Not bigger models, not more parameters. Sketches that turn intractable storage problems into tractable ones, with bounded error.
The longer hydrator list (named only)
Many more hydrators are added in this commit, including handlers for impressed posts, mutual follow signals, followed/inferred topics, starter pack membership, IP, demographics, served history, retrieval and scoring sequences, request timestamps, engagement counts, media metadata, video duration, quote-tweet expansion, follow-of-repliers signals, language codes, and tweet-type metrics.
The pattern, from the two I have read: each hydrator is a thin wrapper around an upstream data store (Thrift service, Strato, Kafka feed) that fetches a specific signal and attaches it to either the query or the candidate. They are small, single-purpose, and parallelizable.
The home mixer chains them together to assemble the full context the model needs.
Implication for the “no feature engineering” narrative
The hydrator pattern is what people mean when they call something “feature engineering in disguise.” The model does not compute these features. The model receives them as inputs after they have been fetched, sketched, bucketed, and proto-encoded by hand-written code. Someone chose to expose MinHash-derived Jaccard scores to the model. Someone tuned the bloom filter false positive rates. Someone wired up the impression surface mapping. None of that is automatic, and none of it is learned. It is editorial choice, executed in Rust.
The model learns the weights on those signals. The signals themselves are still picked by engineers.
The scoring stack: phoenix_scorer.rs, ranking_scorer.rs, vm_ranker.rs
Inside home-mixer/scorers/ there are three files:
phoenix_scorer.rs: routes the ranking request to a specific Phoenix inference cluster and attaches per-action probabilities to each candidate.
ranking_scorer.rs: takes those per-action probabilities and collapses them into a single ranking score.
vm_ranker.rs: an alternative reranker behind a feature flag.
This is where the most important reveal of the May release lives, and I want to spend time on it.
phoenix_scorer.rs: cluster routing is doing more work than you think
I assumed this scorer was a thin wrapper that just called the Phoenix prediction service. Reading the code, the routing logic alone deserves a section.
New-user cluster routing. If the user’s scoring sequence has fewer actions than PhoenixRankerNewUserHistoryThreshold, the request goes to a separate dedicated cluster (PhoenixRankerNewUserInferenceClusterId):
if action_count < threshold {
return PhoenixCluster::parse(&query.params.get(PhoenixRankerNewUserInferenceClusterId));
}There is a different Phoenix model serving predictions for users without enough history. Combined with the new-user OON reweighting I covered earlier, that is two distinct cold-start interventions in the same request:
A separate inference cluster running a model presumably trained or tuned for sparse-history users.
A separate OON weight multiplier amplifying out-of-network candidates after scoring.
Both kick in for accounts younger than a threshold with a minimum follow count. The feed your first week on the platform really is structurally different.
A/B experiment routing baked into the scorer. This was missing from the January release and is now visible:
match configured_cluster {
PhoenixCluster::Experiment1Fou if decider.enabled("override_qf_use_lap7") => {
return PhoenixCluster::Experiment1Lap7;
}
PhoenixCluster::Experiment1Lap7 if decider.enabled("override_qf_use_fou") => {
return PhoenixCluster::Experiment1Fou;
}
_ => {}
}There are explicit experimental cluster codenames (Experiment1Fou, Experiment1Lap7). A decider system can override the assigned cluster for specific traffic slices. This is the A/B testing infrastructure for model variants, and it lives in the scorer.
In the previous deep dive I flagged the absence of experimentation infrastructure in the public code as suspicious. It is no longer absent. They have multiple Phoenix model variants deployed simultaneously, with traffic-splitting controlled by named decider flags.
Egress sidecar with fallback. Production reliability detail I would not have guessed:
let mut predictions = client.predict(cluster, request.clone()).await;
if predictions.is_err() && use_egress {
predictions = self.phoenix_client.predict(cluster, request).await;
}An “egress sidecar” client is the primary path when UseEgressSidecar is enabled. If it fails, fall back to the direct phoenix client. This pattern suggests inference traffic is routed through an egress proxy (likely for cross-region or cross-zone resilience), and the fallback exists because that path can fail independently of the model itself.
Surface awareness. The product surface is set explicitly in the request:
let product_surface = if query.in_network_only {
ProductSurface::HomeTimelineRankedFollowing
} else {
ProductSurface::HomeTimelineRanking
};The Phoenix model sees which surface the request is for (Following feed vs main For You feed) and can behave differently per surface.
ranking_scorer.rs: the hand-tuned weighted sum is still alive
I expected this collapsing step to be a learned model. The 2023 Heavy Ranker famously used hand-tuned weights (”a reply is 13.5x a like, a report is -369x”) and the headline framing around Phoenix was that engineers no longer need to pick weights.
Reading ranking_scorer.rs: that framing is wrong. The hand-tuned weighted sum is still right there, with 22 weighted actions:
favorite * w_fav
+ reply * w_reply
+ retweet * w_retweet
+ photo_expand * w_photo_expand
+ click * w_click
+ profile_click * w_profile_click
+ vqv * vqv_weight
+ share * w_share
+ share_via_dm * w_share_via_dm
+ share_via_copy_link * w_share_via_copy_link
+ dwell * w_dwell
+ quote * w_quote
+ quoted_click * w_quoted_click
+ quoted_vqv * quoted_vqv_weight
+ dwell_time * w_cont_dwell_time
+ click_dwell_time * w_cont_click_dwell_time
+ follow_author * w_follow_author
+ not_interested * w_not_interested
+ block_author * w_block_author
+ mute_author * w_mute_author
+ report * w_report
+ not_dwelled * w_not_dwelledEvery weight is loaded from a config param: params.get(FavoriteWeight), params.get(ReplyWeight), and so on. These are feature switches that engineers tune externally.
Three other pieces of logic in this scorer that matter:
1. Offset normalization (offset_score). If the total weight sum is zero, the score is clamped to non-negative. If the combined score is negative, it gets rescaled by (combined + negative_sum) / total_sum * NEGATIVE_SCORES_OFFSET. Otherwise add NEGATIVE_SCORES_OFFSET to keep everything in a known range. This is how they prevent negative scores from breaking downstream consumers that assume positive ranges.
2. Author diversity penalty (apply_author_diversity). Sort candidates by weighted score, then for each subsequent post from the same author, multiply by:
(1.0 - floor) * decay_factor^position + floorThe second post from an author gets decay^1, the third decay^2, etc. With decay_factor = 0.5 and floor = 0.3, the second post is at 65% of its original score, the third at 47.5%, and so on, asymptoting at the floor. This is the “do not show me five tweets from the same person in a row” rule, and it is hard-coded as a multiplicative penalty in the scorer.
3. Out-of-network reweighting (effective_oon_weight). Out-of-network candidates get multiplied by an OON weight factor before final ranking. Three paths:
Topic requests: use TopicOonWeightFactor
Eligible new users (account age below threshold AND following at least NEW_USER_MIN_FOLLOWING people): use NEW_USER_OON_WEIGHT_FACTOR
Everyone else: use the regular OonWeightFactor
New users get more OON weight because their follow graph is too thin to fill a feed. This is an explicit, code-level cold start handling. The feed actually behaves differently for accounts created recently. That has been an open question for years and is now confirmed in the open code.
vm_ranker.rs: an experimental gRPC reranker with DPP
VM stands for Value Model. The naming is right. But what it actually does was not what I expected.
VMRanker is not an in-process scorer. It is a gRPC client that calls a separate VMRankerClient service. The home-mixer side just builds a RankRequest proto with all the candidate features (including all 22 per-action scores from Phoenix), sends it to the VM service, and uses the returned per-candidate score.
What makes it interesting: the RankRequest carries DppParams { theta, max_selected_rank }. DPP = Determinantal Point Process. This is a diversity-aware reranking method that mathematically promotes candidates that are different from already-selected ones, with theta controlling the strength of the diversity term and max_selected_rank capping how deep the diversity reranking applies.
So VMRanker is two things at once:
An external service that can recompute a single score from the Phoenix action probabilities, with whatever model logic xAI runs server-side (genuinely a learned value model).
A DPP-based diversity reranker that fights the “all similar content” failure mode that pure pointwise ranking suffers from.
The two pieces of evidence that this is experimental and not the default:
It is gated behind EnableVMRanker. Default-off for most traffic.
It has its own cluster ID (VMRankerClusterId) and its own value model ID (VMRankerValueModelId), suggesting they can deploy multiple value models in parallel for A/B testing.
So the production stack today is: Phoenix transformer produces 22 action probabilities. RankingScorer collapses them with hand-tuned weights, applies author diversity and OON reweighting. Final score.
In an experimental treatment: same Phoenix probabilities, but sent to VMRanker instead, which returns a learned scalar with DPP-based diversity reranking baked in.
The implication: the “fully learned ranking” future I assumed was already shipped is actually still being A/B tested. The default in May 2026 is still hand-tuned weights with hard-coded diversity penalties. That is a more honest picture of where production is.
Personal deep dive
I write about ML systems in production — the tradeoffs, the architecture decisions, the stuff that doesn’t make it into papers. If you want to go deeper, the paid tier covers the technical details I can’t fit in free posts.
